About WikiHowNFQA
The WikiHowNFQA dataset is derived from WikiHow, a popular online platform that provides how-to guides on a wide range of topics. The dataset is structured to include a question, a set of related documents, and a human-authored answer. The questions are non-factoid, requiring comprehensive, multi-sentence answers. The related documents provide the necessary information to generate an answer.
WikiHowNFQA is designed for researchers and presents a unique opportunity to tackle the challenges of creating comprehensive answers from multiple documents, and grounding those answers in the real-world context provided by the supporting documents.
Dataset Structure
The WikiHowNFQA dataset is composed of instances, each containing a question, a set of related documents, and a human-authored answer. The WikiHowNFQA dataset is divided into two parts:
QA Part
This part contains questions, answers, and links to web archive snapshots of related HTML pages. It is accessible for downloading on Hugging Face. Each dataset instance includes:
- article_id: An integer identifier for the article corresponding to article_id from WikHow API.
- question: The non-factoid instructional question.
- answer: The human-written answer to the question corresponding human-written answer article summary from WikiHow website.
- related_document_urls_wayback_snapshots: A list of URLs to web archive snapshots of related documents corresponding references from WikiHow article.
- split: The split of the dataset that the instance belongs to ('train', 'validation', or 'test').
- cluster: An integer identifier for the cluster that the instance belongs to.
- related_documents_content: Parsed content from related urls, see Document Content Part below.
Document Content Part
This part contains parsed HTML content from related documents. Each instance includes:
- article_id: The unique identifier of the article on the WikiHow website.
- original_url: The original URL of the web page containing the article.
- archive_url: The URL of a snapshot of the web page from archive.org. The snapshot is the version closest to when the article was created or modified.
- parsed_text: The plain text parsed from the URL in the form of text passages without any HTML text and page structures.
- parsed_md: The text parsed in MD format, which preserves formatting such as tables and lists when extracting text content from the web page.
Dataset Instances
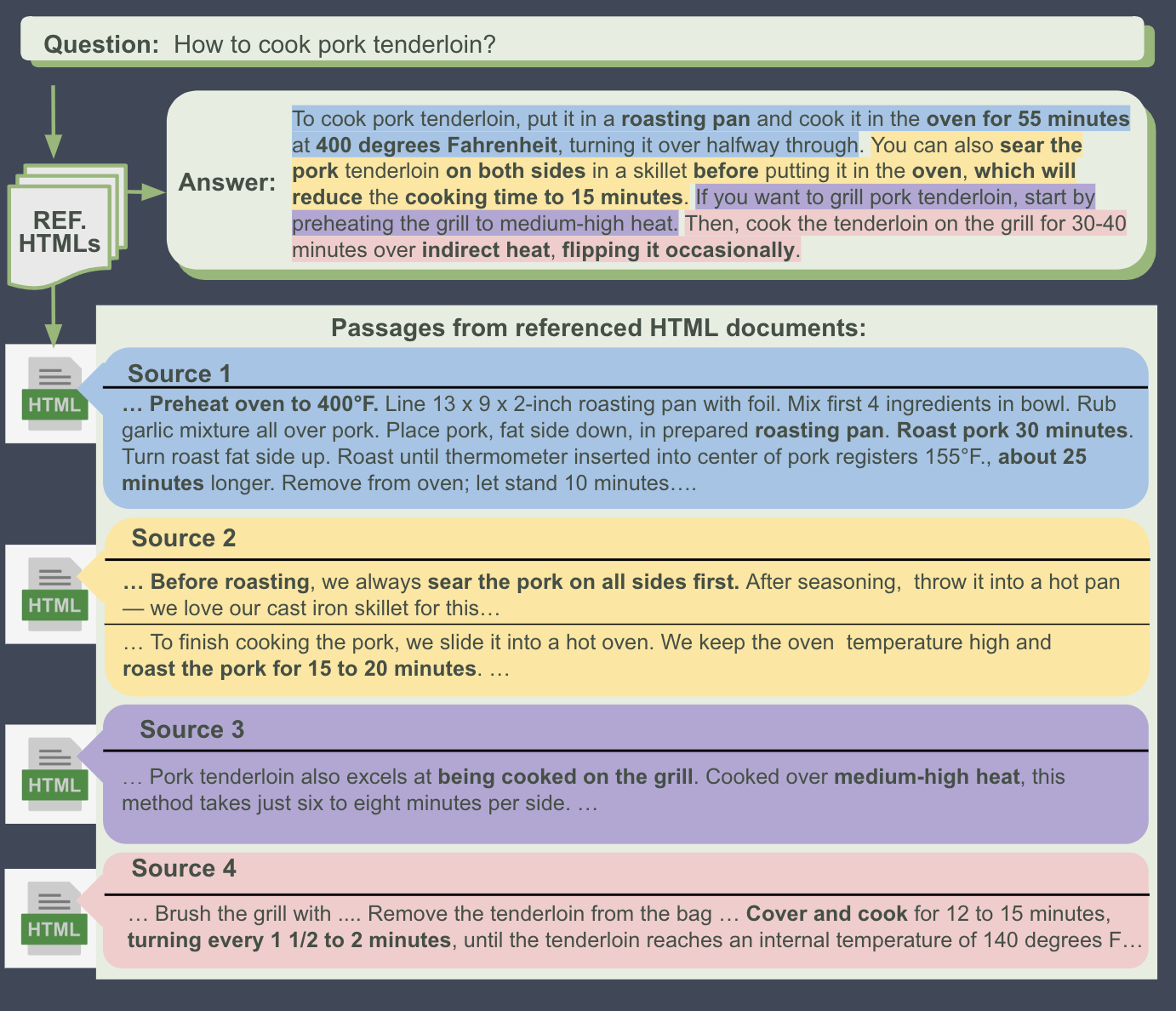
Instance example 1
Article ID: 704295
Question: How To Seal Concrete Floors
Answer: To seal concrete floors, use an epoxy sealer if you want something durable that comes in a variety of colors. For indoor concrete floors that won't be exposed to oil or grease, use an acrylic sealer, which is easy to apply. If you want to seal over concrete floors that already have a seal, try a polyurethane sealer. To seal concrete floors without changing their appearance, you can use a silane or siloxane sealer, which won't alter the color or finish of the floors.
Related Document URLs:
- Make Your Garage Floor Last — The Family Handyman
- Clean Garage Floors – Remove Oil Stains From Concrete
- How to Apply an Epoxy Coating to a Garage Floor
- From Densifiers to Epoxy Coatings
- How to Paint Concrete In 5 Steps
Split: train
Cluster: 2407
Related Document Content:
Title:Make Your Garage Floor Last — The Family Handyman
Passages:
- Sealing your concrete garage floor is the best way to prevent damage from road salt and freezing temperatures. With so many concrete sealing/waterproofing products on the market, choosing the right product can be confusing.
- To get the scoop on choosing the right sealer, we contacted Dave Barnes, president of Saver Systems Inc., a manufacturer of concrete sealing/waterproofing products. Here’s what we learned about the pros and cons of each concrete sealing technology.
- Film-forming acrylic, epoxy and polyurethane products seal the concrete pores and impart a sheen or “wet-look” gloss to the entire garage floor for a really sharp look. These coatings are easy to clean, but they require more rigorous surface preparation. They’re also slippery, especially when wet.
- Silane/siloxane formulas penetrate the concrete and react with minerals to form a “hydrophobic” surface that repels water, road salt and other deicing chemicals. The product won’t darken the concrete or look shiny, so your garage floor will still look like dull concrete.
- This garage is in Minnesota, so preventing damage from freezing water and road salt was critical. We didn’t care about gloss, but we wanted to avoid two steps that are required for many film-forming sealers: acid etching and roughening the surface. We chose MasonrySaver All-Purpose Heavy Duty Water Repellent, a water-based silane/siloxane. It took 5 gallons (about $30 per gallon) to seal the floor of this three-car garage.
- Always start by cleaning the floor with a concrete cleaner and power washer (Photo with step 1). If you have oil stains, treat them before you power wash (see how to remove oil stains here). Then apply the sealer with a paint pad to get an even application and avoid puddles (Photo with step 2). After it dries, fill floor cracks with a polyurethane crack filler (Photo with step 3).
- Mask the walls with poly. Then use the power washer to apply concrete cleaner. Scrub garage floor with a push broom. Then rinse with high pressure and a 40-degree nozzle. Squeegee and let dry.
- Caution: To avoid electrical shock or carbon monoxide poisoning, always locate your power washer in an open area outside the garage (as demonstrated in photo above).
- Dip the paint pad into the sealer of your choice (we chose silane/siloxane) and spread it evenly across the garage floor to avoid puddling. Let the product soak in and dry.
- Cut a small opening in the tube tip (we used urethane caulk). Then hold the caulk gun perpendicular to the floor, pressing the tip into the crack. Squeeze the trigger and force the crack filler deep into the crack.
Title:Clean Garage Floors – Remove Oil Stains From Concrete
Passages:
- Oil and grease stains don’t just make a garage floor look bad- they can also cause falls, ruin your shoes and get tracked into the house. And if you want to finish your floor with a coating, it’s essential to get rid of oil deposits for a good bond. Solvent-based remedies are harmful to the environment and can damage the concrete surface. Cat litter, sawdust and other absorbent materials remove standing oil but do nothing about the oily stain left behind. Commercial and household detergents require a lot of scrubbing and can leave behind residue or discolor the concrete. Here are two product that actually work.
- To remove oil spots, make sure the concrete is dry and trowel on the Pour-N- Restore garage floor cleaner product 1 in. beyond the stain’s perimeter. Let it dry to a powder, a process that can take eight hours or longer.
- Sweep up the powder once it’s completely dry. Then allow all moisture to evaporate completely. If the product is used on sealed concrete, evaporation can take several weeks. If stain remains, repeat the application.
- Pour-N-Restore, which combines a citrus degreaser with a non-leaching absorbent, is one option. It’s easy to use and it works well for spot-cleaning smaller stains.
- Scrape any standing oil, sand or grit off the spots using a stiff plastic scraper or putty knife and sweep the area clean. Provide good ventilation and wear eye protection, gloves and a dust mask. Spread Pour-N-Restore on the stain with a 1/4-in. notched trowel and let it dry (Photo 1). It can take eight hours or longer to dry depending on the temperature and humidity (for best results, use this product at temps above 60 degrees F). Once it dries to a powder, sweep it up (Photo 2) and throw it into the household trash. Let the moisture from the area evaporate completely, which can take a few days, and the stain should be gone. If the stain remains, reapply the product and scrub it with a push broom or nylon bristle brush. Let it dry, then sweep up the powder and throw it into the trash.
- Spray and wait five minutes before rinsing. If the oil spot has a heavy grease buildup, scrub the spot with a stiff nylon bristle brush (not a wire brush, which can scar the finish) before rinsing.
- You can use Griot’s Oil & Grease Cleaner to clean and degrease small spots or your entire garage floor. It worked wonders on our oil stains. And the stuff is so mild that it won’t harm grass or plants and can be safely washed down the storm sewer, making it suitable for use with pressure-washing systems on larger areas. It’s also easy to use: You just spray the liquid on the spot, wait two to five minutes and then spray clean with a hard blast of water. Available at griotsgarage.com and auto parts stores.
Title:How to Apply an Epoxy Coating to a Garage Floor
Passages:
- If your garage floor has seen better days, you might consider sealing it. While there are many products available, we used a two-part epoxy kit from Rust-Oleum. The kit contains everything you need to have your garage floor looking like new including cleaner, two-part epoxy coating, decorative paint chips, and even an instructional DVD.
- The epoxy coating won’t bond well if the floor has already been sealed, so test it first by pouring a little water on the floor. If the water beads up, the floor has been sealed before.
- You also should check for excess moisture in the slab by taping a 2’ by 2’ piece of plastic to the floor for 24 hours. If the area under the plastic appears damp, then the epoxy might have problems adhering. Newly poured concrete should cure at least a month before sealing.
- Not only will sealing the floor improve the look of your garage, the smooth surface will be much easier to sweep and keep clean.
- Backed by his 40-year remodeling career, Danny served as the home improvement expert for CBS’s The Early Show and The Weather Channel for more than a decade. His extensive hands-on experience and understanding of the industry make him the go-to source for all things having to do with the home – from advice on simple repairs, to complete remodels, to helping homeowners prepare their homes for extreme weather and seasons.
- sorry I just read the entire blog again and realized you answered that with the plastic test. Does Durolock (sp) waterproofing help in a situation like this. It claims that if used to thier specifications you can use acrylic floor paint on top and it will stick regardless of hydrostatic pressure..any comments? I am just now trying to get carpet glue off the concrete flooring after a flood in our lower level..the idiots that installed it used carpet tacks AND then used an enormous amount of adhesive for some reason. Jasco is taking it off but ive decided to rent a diamond grinder with three heads and an attached wet vac and hopefuly will do the eight hundred sf i need to do in a weekend..all five feet two inches of me. ( no woman tells thier weight)
- WHAT IS THE BEST PRODUCT TO USE ON MY GARAGE FLOOR TO LEVEL IT OUT CORRECTLY BY THE DOOR. THE PROBLEM I HAVE IS WHEN IT SNOWS IT MELTS AND SETTLES IN MY LOW SPOTTS. WHAT IS THE BEST PRODUCT AT HOME DEPOT TO LEVEL IT OUT? THANKS
- Greg Is the problem the floor or a drainage issue? The solution I would suggest would be to dig drains at the entrance to your garage, covered by grates so that when you drove over them, you would be able to do so with ease and then direct the drainage into a sump pump. The only way to level the floor at this point is to resurface it I believe with an expensive overlayment which is attractive but about twenty dollars a sf depending upon the area you live in. If the water isn’t too much of an issue maybe putting a better seal on the bottom of the garage door would help. I know we did that and it helped a great deal. It is so tight the water delivery people think it’s locked when they deliver water for our drinking fountain. But it does help to some degree.
- I have my garage issue. I do have hyrdrostatic pressure and it may have been caused by a bad wax ring in nearby bathroom. It has caused our flooring to buckle (wood flooring),existing to when we bought the house, now I want to paint or seal the garage flooring. Every time i go in there barefoot my feet are white and drag into the house. Do I need a contractor to further look into more problems. My husband has placed draing rocks to the side of the house due to swamp cooler. Too many wet problems here. Help my sobbiness.
- I believe I have water coming up from under my garage floor, although it is peculiar. It can pour down rain and the floor is dry, humidity and it gets wet. When I leave a box or anything on the floor and move it after a couple of days the spot is damp. Any suggestions?
- I’ve seen homeowners in warmer climates simply lay out a end roll piece of vinyl flooring that they’ve acquired as a remnant. One can get years of use before replacing and no real labor issues. Nothing better for clean-up issues, wet or dry.
- My garage floor shows a crack in it. It appears to come from the outside wall about half way in the garage. Also, lots of water comes off the trucks wheels from melted snow or just rain water. What is the best thing to do in this case?
- I recently purchased a new home and the garage floor has never been sealed. The problem is, is that it’s October and it’s about 40 degrees outside. Is this to cold to seal a garage floor? I live in Ohio and the winters here are usually pretty bad and alot of melted snow and road salt. I wanted to park my car in the garage this winter, so hopefully I can seal a floor in cold weather. I’m not painting the floor, I just want to put a coat of standard sealer down. Please let me know what I need to do, and if it’s a bad idea to park my car in the garage without sealing the floor first.
- I would like to know the answer to Nick’s question. I am in Minnesota. I close on my house 12-5-08 and I would like to seal the garage floor before the first snow and salt gets on it. What do I do??
- I purchased a split level home two years ago. The garage floor, although level, has cracks in floor, and is allowing water sepage to occur, resulting in large puddles of water on the garage floor. What is the best plan of attack? To have the floor sealed, or do I need more drastic measures?
- We recently purchased a house, but by the garage door, the concrete is pitted and snow blows in. Some of the pits are up to an inch deep. Once it warms up I would like to fix the concrete and seal it so we don’t have problems again next year. Would a concrete patch work or will the sealer adhere to it?
- * Ben Erickson January 15, 2009 at 8:39 am Don, You might want to consider using a concrete resurfacer, like Danny did in the video How to Repair Cracks in Concrete.
- I did my garage and basement myself last year. I took some pretty extensive photos of the entire process, which folks may find useful here: http://www.goodrum.cx/fall2007projects The epoxy flooring project is about halfway down the page.
- * Ben Erickson April 27, 2010 at 1:00 pm Hi Mario, If your garage floor has concrete sealer on it (i.e. water beads up), two-part epoxy products may not adhere properly and shouldn’t be applied. If the floor has been painted, epoxy products can be applied if the old paint is adhering well to the concrete and has been scruff sanded first. To test whether old paint is adhering well, cut an “X” through the old coating, press a piece of duct tape firmly down over the cut, pull the tape off in a quick motion. Don’t apply epoxy finish over it if more than a quarter of the paint comes off on the tape. Good luck with your project!
- I cannot get to all the sides without moving some heavy equipment. If I do most of the floor but leave one side without sealer will the rest of the floor stay pretty dry or will there be a lot of sweating from the unprotected area, etc. Said another way, does the floor stay dry where I seal it even if spot treated? Thanks. Gary
- I’m wanting to apoxy my garage floor and have a smoot finsh but I need to know if the expantion joints need to be filled first and if so what ia the best thing to use.
- WHAT CAN I USE ON A GARAGE FLOOR THAT HAS BEEN SEALED TO GIVE IT A COLOR FINISH.THIS IS A 5 YR OLD HOME. I HEARD EPOXY SHOULD NOT BE USED
- The previous owner had painted the garage floor with a white paint, it looks like crap now. Do i need to get ALL the paint off before i can seal it?
- We just purchased a brand new home in Pennsylvania and wanted to know the same thing as Nick and Larry above- Can I seal my garage floor in cold temperatures? Thanks!
- * Ben Erickson December 14, 2010 at 10:27 am Hi Ann, That will depend on the particular product you use, so check the label or contact the manufacturer to find out. According to Rust-Oleum, the epoxy product featured in this video should not be applied when the air is under 60° F or the concrete floor is below 55° F.
- I recently purchased a home and water in my garage (from snow melting) is draining towards my house foundation. I recently discovered that moisture is getting through the concrete block foundation and affecting the drywall (little moisture spots are visibly apparent).
- Do you know if sealing my garage floor would prevent water from seeping down along the foundation? i.e. would the sealant be strong enough to not let any water penetrate?
- I read its best to wait at least 30 days of curing time of a new concrete slap before application of epoxy, but I just resurfaced an existing concrete floor with an ultra thin layer of cement, how long should this cure before paining on water-based epoxy?
- I know these are older comments but I had all these similar questions and I came across Epoxytech they are pretty good. Part I liked best is that I could get a hold of them at night when I was off work while investigating epoxy floor coating for my garage and they answered my questions for me and my floor turned out fantastic. If anybody comes across this article give them a call I’m sure they will answer any question you have. http://www.epoxytech.net is their website. Hope you had the success I did.
- We have a carport attached to our home. Every time it rains (or even looks rainy, the concrete gets very wet and slippery. What should we do to correct this problem.
- I would like to do my garage floor but its pitted and very dusty , how should I approach this ! I would like to seal and paint!
- * Thomas Boni August 1, 2018 at 10:00 am Hi, Billy! If the garage floor is a concrete slab, you would simply resurface it. Here’s a video on that process! https://todayshomeowner.com/video/repairing-damaged-concrete/
- We applied an epoxy kit to our garage floor but have two places that came darker then the rest? We cleaned and everything prior to applying, and there was no oil stains. Just wondering if there is any way in fixing it
- * Thomas Boni January 3, 2019 at 11:47 am Hi, Holly! What a great question! We recommend submitting questions about unique situations like yours to the Today’s Homeowner Radio Show. Please use this form to contact Danny Lipford, America’s Home Expert, directly: https://todayshomeowner.com/radio/ask-questions/ Take care!
- gentlemen,a few months ago I applied concrete cement on the floor of my shower because was cracking up,since it is a little slippery I would like to apply an epoxy mixing it whit sand and apply on the shower base. is it there any epoxy that wont peel off after apllying it thank you Alfonso
- * Thomas Boni August 16, 2019 at 8:30 am Hi, Alfonso, Epoxy peels after application for many reasons. Among these are a poorly prepared concrete surface, moisture in the concrete surface, a dirty surface due to acid etch residue, and sealed (but not grinded) concrete. We encourage checking your local home center, asking questions and ensuring the products to correct these issues match your home’s needs. Good luck!
- I just sealed my garage floor with a 2-part epoxy and completed the job with the decorative chips etc. It looks great. Should I now seal it with a clear coat on top? If so, what product is recommended?
- * Thomas Boni September 13, 2019 at 9:12 am Hi, Ron, It sounds like it looks great! 🙂 We do recommend adding a high-gloss coating or protect your hard work. Here’s one from Quikrete: https://www.quikrete.com/productlines/epoxy-high-gloss-coating.asp
- Many homeowners can install flooring, but transitioning from one surface to another is a challenge. This molding kit can help. Watch Jodi Marks' review!
Title:From Densifiers to Epoxy Coatings
Passages:
- A garage floor sealer sounds simple enough if you want to protect and seal the concrete in your garage. But what does a sealer do for the concrete and which type should you use? Which sealer is best for your requirements and budget? Options include densifiers, siliconates, oil repelling sealers, salt repelling sealers, epoxy, polyurea, acrylics, and more. Getting bewildered yet?
- Don’t fret, it’s not as confusing as it may seem at first. Our goal is to explain the differences in sealers for a garage floor. We will discuss how they work, how they are applied, and the benefits of each to help you determine what sealer will be best for your needs.
- This includes economical sealers that protect the bare concrete for a nice clean look, sealers for working garages and workshop floors, as well as decorative sealers and coatings. That’s right, garage floor coatings are sealers as well.
- There are two distinct categories of garage floor sealers that determine performance, looks, and application requirements. They are penetrating sealers and topical sealers.
- Penetrating sealers work by penetrating into the concrete upon application. They react with the minerals in the concrete to form a hard, gel-like molecular barrier at the subsurface. Otherwise known as non-film forming sealers, they are breathable and do not form a coating on the concrete surface.
- As a result, penetrating sealers do not change the look of bare concrete. And because they are non-film forming, they cannot be scratched if you drag a sharp object across the concrete surface. In addition, they will retain the same wet slip resistance of the current concrete surface.
- Furthermore, penetrating sealers typically are the most economical sealing solution for a garage floor and one of the easiest of all garage flooring options to apply.
- An important fact about penetrating sealers is that they are not waterproof as some people assume. Nor are they stainproof. This is due to the non-film- forming properties of the sealer.
- Though they do a good job of repelling water and resisting automotive fluids, all liquids will eventually penetrate the concrete surface if allowed to sit long enough. How long they sit before penetration is determined by the type of sealer and the porosity of the concrete.
- Lastly, liquids such as oil, automotive fluids, and other contaminants can stain if allowed to sit. How much they stain and how easy an oil stain cleans up are determined by the type of penetrating sealer applied and how long the oil or other contaminant was allowed to sit.
- When it comes to stain resistance, the goal of a penetrating sealer is to provide enough time for spills and leaks to be cleaned up first before they have a chance to stain. This includes some of the newer oil repelling sealers the industry has introduced to provide better stain resistance.
- Topical sealers adhere to the concrete surface with only slight penetration. Also known as film-forming sealers, they are more widely known as floor coatings or garage floor coatings. They form a protective layer that is typically non-breathable and can be impermeable depending on the coating used.
- Many are 2-part resinous coatings that require mixing before application, though there are exceptions. They chemically cure and create a hard coating that is extremely durable. The thickness, abrasive properties, and chemical resistance of these coating sealers can vary depending on the type and quality of the coating that is used.
- Most coatings are also considered decorative. Clear coatings will enhance the look of the garage floor surface. They tend to darken bare concrete, add character, and provide a matte to glossy finish.
- In addition, clear coating sealers are used to protect and highlight the colors of stained or dyed concrete. They make the colors pop with vibrancy and add shine.
- Colored coatings completely change the look of the garage floor. Epoxy and polyurea garage floor coatings are great examples. You can opt for a solid color or add multi-colored acrylic flakes with a clear coat to create your own unique color palette.
- Unlike penetrating sealers, topical sealers and coatings prevent the bare concrete from being stained by oils, automotive fluids, and chemicals. This is because the coating acts as a sacrificial barrier.
- Furthermore, one large advantage of topical sealers over penetrating sealers is that the surface is very easy to keep clean.
- Higher-performing coatings can also be extremely stain resistant. Oil, chemicals, salty road brines, and other fluids can sit for much longer periods. All that is required in most cases is wiping up the mess with a rag. A shot of Windex can remove any leftover film residue.
- Lastly, many topical sealers and coatings will prevent the penetration of water and liquids into the concrete. This doesn’t necessarily make the entire garage floor waterproof. Exposed cracks and concrete joints can still allow water to seep into the concrete.
- Now that we better understand the difference between penetrating garage floor sealers and topical garage floor sealers, let us discuss the various types available and what we can recommend.
- To our Reader’s: This post may contain affiliate links. If you use these links to make a purchase, we may earn a small commission. As an Amazon Associate, All Garage Floors earns from qualifying purchases. You can read our full disclaimer here.
- There is a wide range of penetrating sealers for concrete to choose from. Therefore, it can easily become overwhelming if you don’t know what to look for.
- There are silane concrete sealers, silicone sealers, siloxane sealers, siliconate sealers, densifiers, oleophobic concrete sealers, and more. Many are hybrids of each. Some are water-based, while others or solvent-based. Many do not work very well for a garage floor.
- As a result, we will only discuss those penetrating sealers that we recommend and know to work best for a garage or workshop floor. In addition, we will discuss concrete prep that may be required and sealer application.
- Siliconate sealers are a great choice for homeowners who just want good general protection of their bare concrete at a minimal cost with ease of application. Often considered the “all-purpose” sealer for garage floors and workshops, they are a great value as well.
- Compared to other penetrating sealers, their medium-sized molecular structure does not allow the sealant to penetrate too deep. This provides for better coverage rates and more importantly, better protection of the concrete surface.
- As a result, they provide good water repellency including repellency against, moisture, road salts, and dirt. Siliconate sealers also resist efflorescence and provide good protection against freeze-thaw, which is the leading cause of spalling of concrete.
- One thing to keep in mind is that siliconate sealers do not repel oil. Though they will buy you some time for cleanup by slowing down penetration into the concrete, a stain can occur if oil is allowed to sit for long. However, the resulting stain will not be nearly as bad as an oil stain on untreated concrete.
- As with the majority of penetrating sealers, the application is very easy. For most concrete surfaces, the only preparation required is to clean and degrease. Once the concrete has thoroughly dried, one coat of the sealer is applied using a low-pressure pump-up garden sprayer with a conical spray nozzle.
- Densifiers are a type of silicate sealer. They had been used primarily in the process of polishing concrete and for adding strength to newly poured concrete floors. However, with the introduction of easer to apply lithium silicate densifiers, they have become more popular for garage, workshop, and warehouse floors.
- Densifiers work by reacting with minerals in the concrete to form a very hard substance called calcium silicate hydrate or CSH. The CSH fills many of the empty voids and pores of the concrete at and near the surface. This increases the density, strength, and hardness of the concrete in these areas.
- In addition, the filling of these voids with CSH reduces concrete dusting. Furthermore, it slows down moisture intrusion from below the slab to help prevent efflorescence and moisture vapor. However, silicate densifiers do not repel water or other liquids.
- As a result of their increasing popularity, manufacturers began adding siliconate to densifiers to provide water and liquid repelling characteristics. This new type of densifier with siliconate sealer added provides the characteristics of a densifier plus, the same protections as a siliconate sealer as well.
- As with siliconate sealers, densifiers do not repel oil. However, testing has shown that densifiers with siliconate sealer added do a better job at resisting oils stains than a stand-alone siliconate sealer only.
- Application is similar to that of a siliconate sealer. However, more importance is emphasized to not let the densifier puddle. If it does, it’s important to use a paint roller to roll out the excess or use a broom to work it into the concrete.
- If allowed to dry with excess sealer on the surface, a white powder will form and requires heavy scrubbing to remove.
- Oil repelling penetrating sealers are fairly new to the market. They’ve come about due to the constant demand for a better performing sealer against staining from oil and other automotive fluids for garage floors and workshops.
- A unique ingredient of these sealers is the use of fluorocarbons to create an oleophobic barrier. Oleophobic refers to the physical property of a molecule to seemingly repel oil.
- Oil will lay flat or even run on a concrete surface treated with typical penetrating sealers. This characteristic does not resist the penetration of oil nearly as well as water which typically beads from being repelled.
- However, oil tends to bead somewhat on a concrete surface treated with an oleophobic sealer. This repelling action allows the oil to sit for a longer period with less chance of penetration into the concrete.
- This repelling action allows for an easier cleanup of oils and other automotive fluids and less chance of an oil stain. However, this does not mean the concrete can’t be stained. As with all penetrating sealers, oil and other offending contaminants will stain eventually if allowed to sit long enough.
- What oil repelling penetrating concrete sealers do is allow more time for the oil to sit before cleanup. In addition, it can also make the removal of any offending stains easier.
- The raw materials used for oil repelling sealers are more expensive. As a result, these types of sealers cost more than typical penetrating sealers. In addition, one popular oil repelling sealer that is known to work well also requires the application of a densifier first.
- Oil repelling sealers in most cases are the better choice to use on garage floors and workshops. However, the importance of oil repelling characteristics versus cost is something to consider if you are on a budget.
- Application of these sealers is a bit more involved but still fairly easy. The concrete must be degreased, clean, and dry. Depending on the sealer used, the application can require a wet flood coat using a pump-up sprayer or application via a lambswool pad or microfiber pad.
- The number of options for garage floor coatings and topical sealers is large. There are acrylic coatings and sealers, epoxy, polyurethane, polyurea, and polyaspartics. In addition, there are single-part moisture-cured coatings and 2-part coatings, not to mention clear or colored.
- As a result, this is an area where research before a purchase is paramount. Marketing campaigns by large corporations such as Rust-Oleum, Behr, QuikRete, H&C, and others have only served to confuse the consumer. This has lead to many unhappy or misinformed purchases.
- In addition, do not rely on information from your local home improvement center. They are not knowledgeable about concrete coatings and they do not carry quality products in their inventory.
- Acrylic concrete sealers form a thin protective layer on bare concrete. Most are clear, but some can be tinted for color. Expect 1 – 1.5 mils dry film thickness per coat on average.
- They will enhance the look of the garage floor and make the concrete look slightly darker. The floor will attain a somewhat wet and glossy look or you can opt for a less flashy matte finish. Glossy finishes tend to be more durable.
- In terms of performance, acrylic sealers will protect the garage floor from water and chloride intrusion. In addition, they provide light to moderate protection against oil, vehicle fluids, hot tire pick up, and road salts.
- Most acrylic sealers are also U.V. stable. This means that they will not turn a yellow tint if exposed to direct sunlight.
- Water-based acrylic sealers are the least durable of all concrete coating options and the easiest to scratch. Solvent-based acrylics increase durability, scratch resistance, and chemical resistance from automotive fluids.
- For a more durable alternative, we recommend the performance of MMA acrylic sealers. These have longer endurance properties than standard acrylics sealers and can withstand harsher chemicals.
- Acrylic sealers perform best with light to moderate traffic. Reapplication may be required once every 18 to 36 months depending on the sealer used.
- One DIY advantage to acrylic sealers is that they are fairly easy to apply. The concrete needs to be degreased, clean, and dry. Etching of the concrete is typically not required unless the surface is extremely smooth.
- You can use either a low-pressure pump-up sprayer or apply it with a paintbrush and rollers out of a tray. The key to a successful application is to apply the coating thin or problems will develop. Typically, two coats are applied for the best protection.
- If you like the look of a clear sealer on bare concrete, then one of the best performing values is a modified acrylic polyurethane.
- This is a somewhat new sealer for garage floors that we feel is going to explode in popularity once the word gets out. It combines high performance and ease of application at a budget price.
- Technically, they are a thin, 2-part water-based, high-performance, acrylic modified, aliphatic polyurethane coating and sealer. Aliphatic means that they are U.V. stable and will not amber. In addition, they are Eco friendly and no etching of the concrete is required.
- Acrylic modified polyurethane sealers provide better abrasion resistance, chemical resistance, and stain resistance than most epoxy. They are a true workhorse sealer for garage floors and workshops.
- A minimum of two thin coats is required. This will result in a dry film thickness of just under 2 mils. Three coats are recommended for commercial applications. They are one of the few topical sealers that will adhere well to machine-troweled concrete.
- These are best used on smooth concrete with few repairs. Due to their thin nature, they are not recommended on rough garage floor finishes or concrete with numerous repairs. They are not thick enough to provide self-leveling properties such as epoxy or polyurea.
- Furthermore, they will only adhere to bare, unsealed concrete and are not compatible as a clear sealer over epoxy or other coatings.
- Application requires that the concrete be clean and dry. No etching of the concrete is required. The sealer is best applied using a low-pressure pump-up sprayer with a conical spray nozzle in conjunction with a microfiber application pad or 1/4′′ low nap roller.
- Undisputedly, the most popular sealer is garage floor epoxy. Epoxy is a 2-part thermosetting resin that is applied as a coating. It chemically cures to create polymer structures that are closely cross-linked. This is what gives epoxy its superior strength and durability.
- Epoxy is available as a clear coat to bare concrete but is more commonly applied in solid colors. Finishes range from satin for low-budget formulas to a high gloss for commercial quality epoxy.
- The most durable applications are epoxy systems that include a minimum of a color coat, optional decorative color flakes, and a clear coat. Professionally installed garage floor coatings consist of such systems.
- In addition, epoxy coating sealers are much thicker than acrylics. They can be applied thicker than any other coating available. Depending on the solids content, one coat of epoxy can be applied at 2.5 – 12 mils dry film thickness and higher.
- Epoxy sealers can withstand heavy traffic and are abrasion resistant. Furthermore, most are non-breathable and will prevent water and chemical intrusion at the surface. They are resistant to most chemicals, oil, vehicle fluids, road salts, and hot tire pick up.
- One disadvantage is that epoxy is not U.V. resistant. If exposed to direct sunlight or strong indirect sunlight, it can turn a yellow tint (amber) over a period of time.
- Single coat DIY garage floor epoxy kits purchased from local home improvement centers are the least durable epoxy coatings. We explain more in detail here.
- Epoxy sealer application is more involved and time-consuming compared to penetrating sealers. However, DIY application is very common. Application is done using paintbrushes and paint rollers.
- Proper concrete preparation is essential or the coating will not adhere properly. Etching the concrete is required at the minimum. Grinding of the concrete may be preferred for some applications, but it is not mandatory.
- In addition, epoxy application is time sensitive. Once the two parts are mixed, you typically have 30 – 40 minutes to get the epoxy applied before it hardens up. Low-quality epoxy allows for more application time. This time limit is dependent on the solids content. The higher the solids content (thicker, higher-performing coatings), the less time you have to apply it.
- Polyurethane is a high-performance coating with increased benefits over epoxy. Depending on the quality, it is typically more abrasion and scratch resistant than epoxy. It wears longer and is more chemical and stain resistant. And unlike epoxy, most polyurethanes are U.V. stable and will not amber.
- Traditional polyurethane coatings are available in 2-part formulas or single- part moisture-cured formulas. Like acrylics, they are applied thinly with an average dry film thickness of 2-2.5 mils.
- However, one issue with traditional polyurethane concrete coating sealers is that they do not bond well directly to concrete. Instead, they are used as a U.V. stable colored coating over epoxy or more commonly, as a clear coat over epoxy.
- Fortunately, this bonding issue has recently changed with the introduction of newer moisture-cured polyurethanes designed specifically to bond directly to concrete. Moisture cured coatings are single-part and do not require mixing in a second part to act as a catalyst to start the chemical curing process.
- Instead, it uses moisture in the air as the catalyst. The coating is not activated until it is applied to the concrete and exposed to the moisture in the air. As a result, you have a much longer working time to apply the coating as compared to epoxy. This is a nice benefit for DIY installations.
- Because these coatings are thin, they typically require a minimum of two color coats. One clear coat is sufficient if being applied to bare concrete. However, two are recommended for more durability if it’s a busy working garage or workshop.
- This type of coating sealer will not do a good job of hiding irregularities in the concrete due to its thin nature. High solids epoxy is better for that.
- Application of direct to concrete moisture cured polyurethane sealers is varied. The concrete must be clean, degreased, and completely dry throughout.
- In addition, most require that surface be acid etched. However, polyurethanes such as DuraGrade Concrete by Rust Bullet do not require etching in many cases. This can be a huge benefit to DIY installers that do not want to deal with additional concrete prep. Like most coatings, it is applied with paint rollers and brushes.
- Last on the list is the newer polyurea and polyaspartic floor coating sealers. These are a sub-group of polyurethane and have a similar finish to epoxy and polyurethane coated floors.
- They are U.V. stable and can provide better protection than polyurethane. They also provide the best resistance against brown tire prints in the coating.
- Unlike epoxy and polyurethane, many of these coatings can be applied in extreme temperatures from below freezing to over 100 degrees, depending on the formula.
- What makes these coatings popular is their extremely fast return to service times. They can be installed on your garage floor in one day and driven on the next. Most polyurea and polyaspartic coatings need to be applied by a professional due to their very short working time. Twenty minutes or less is typical.
- There are newer polyurea coating sealers that have been introduced that are much more DIY friendly. They can provide up to two hours to get the coating applied depending on the polyurea or polyaspartic formula.
- These long application times reduce the common anxiety of getting the coating applied in enough time. As a result, they can be an excellent choice for a DIY application.
- We highly recommend the newer single-part polyurea coatings. These are commercial quality, moisture-cured coatings that will last 10-15 years or more on a garage floor.
- We have a few considerations for you to keep in mind when deciding which garage floor sealer is best for you.
- If you have issues with moisture coming up through the concrete, a penetrating garage floor sealer is generally the better choice. Because they are breathable, they will not be affected by moisture vapor. As we discussed, they may also serve to block or reduce moisture coming up from underneath the concrete slab.
- Acrylic sealers are breathable and will tolerate low levels of moisture. Resinous topical sealers and coatings such as epoxy, polyurethanes, and polyurea will not allow for moisture transfer. They can peel and even pull small chunks of concrete up with it if moisture gets trapped under the coating. Moisture testing should be conducted if you suspect it may be an issue before applying a topical sealer.
- If you use your garage or workshop for metal fabrication and welding, a penetrating sealer may be the better option. Coatings will get damaged if sharp metal objects are dragged across the surface. They will also incur burn marks from welding slag or heavy metal grinding.
- Lastly, take the time to evaluate your requirements. Be realistic in terms of what you want a concrete sealer to do for your garage floor or workshop. No penetrating or film-forming topical sealer and coating are perfect. Compromises may need to be made, particularly if budget is a concern.
- We just finished painting our garage. The garage floor is 15 years old. We have some oil, polyurethane stains, and paint stains. I am looking to degrease and clean how you list above. The question I have is: I only want to reseal the concrete with a densifier. If I am forced to diamond grind the concrete, will I have swirl marks showing or will the grind marks not show?
- Hi Craig. Densifiers do not change the look of the concrete at all. What ever it looks like when dry is exactly how it will look after the densifier is applied and has dried. If you have to remove the polyurethane and paint via mechanical means, I would suggest using the least aggressive method. Concrete hit with a concrete grinding wheel is going to appear much different with possible swirls marks and will be lighter in color. You may want to try using 60 grit sandpaper instead. Sandpaper can still remove some thin paint, but does not do much to the concrete. The concrete usually tears up the sandpaper with not as much effect to the surface of the concrete.
- Hello, we have some pitting in our concrete due to age and salt (we’re in New England) – can we seal a pourous surface with epoxy? or is it required that we use another product? Thanks! – Pat
- Hi Pat. If the concrete is clean and porous enough, then yes, you can seal the surface with an epoxy coating. It would need to be a quality high solids epoxy though and not the type of product you can purchase from a home improvement center. The coating is not going to level surface though if that is what you were thinking. You would need to use a special epoxy sand slurry to do that first.
- I just painted my garage floors and placed chips like flakes. Which is the Best sealant to place on my floors.
- I am remodeling my enclosed garage into a playroom / bedroom and want to seal the concrete . I also will have to raise it up with plywood and flooring. I live in a very humid climate. Need advice on the best dyi concrete sealer. Thanks
- Hi James. What are you trying to accomplish exactly when you say you want to seal the concrete? It sounds like the flooring is going to be raised above it. Do you have moisture issues?
- Thanks Shea, just bought the house 5 months ago. I don’t think I have serious moisture issues but want to be proactive and be sure not to. I thought to put a sealer on the concrete then plastic cover and then plywood and then vinyl flooring. What are your thoughts and recommendations. Thanks for your help. James.
- OK, then we would recommend applying a densifier with siliconate sealer added. The densifier works by filling capillaries near the concrete surface to help combat moisture intrusion from below. The added siliconate sealer helps to seal the surface from moisture on top of the surface. It’s easy to apply and relatively inexpensive. This article here discusses a product that we recommend.
- I have read with interest many discussions here and all has been very helpful. I have a new garage floor I will likely use a densifier (L3000) + Ghost shield 8510 on. I expect the structure to be finished by mid September with lighting to go in shortly after. That will put the age of the concrete at about 60 days. My question is how long do I need to wait before treating a new concrete floor? Is 60 days enough?
- Hi Vin. Yes, waiting 60 days is good. The typical minimum wait is 30 days for a standard 4′′ concrete slab.
- Hi. I was wondering what the best sealer was for a cement garage floor that is not slippery. I am looking to seal my mom’s garage, but she is older and I don’t want her to fall. My dad use to do it but he has passed away and I am not sure what he used. Thanks for any advice!
- Hello Beth. If you are just looking to seal the concrete without a decorative appearance, then we highly recommend a siliconate sealer (not silicone). You can read about this type of sealer here. We even have a product recommendation that works extremely well. These are easy to apply and not expensive.
- Can I polish my garage floor, to 800 grit, and then use clear polyurea as my sealer? I like the look of the polished concrete but want improved functionality with the polyurea.
- Hello CJ. No, that is far too fine a grit for coatings to penetrate and bond. ArmorPoxy has said that their SPGX polyurea will work with a 100-120 grit hone, but that is it. Others need 80 grit or less. You would need a stain guard sealer for something that fine. It’s technically not a coating, but it does leave a micro thin layer at the top that can be polished to a gloss. Stain guards are commonly used on polished concrete all the way up to 3000 grit.
- Hello, I have a car port, enclosed on three sides. I have PVA the floor to seal it. I ve been told that this may not be suitable for long term use, especially when the car is driven in wet. Is there something you can suggest to over this, that will dry clear. So not paint. Many thanks
- Hello Mrs. Courtney. A PVA sealer is not the best idea for a garage floor or car port, particularly if you are not going to paint over it. It’s used as a primer and is not intended as a wear surface and will leave the concrete a whitish hue. If you haven’t applied it yet, we would recommend using an acrylic sealer instead.
- I need to seal and finish a busy hospital hallway vct tile and quick in and out I was thinking one coat of sealer and two coats of finish would this be ideal?
- I just had the concrete floor in an old house from the 1960’s ground, stained, epoxy applied, and a coat of polyurethane applied. It’s June, the weather is warm but humid and the polyurethane top coat didn’t dry for 2 1/2 days. The medium dark floor now has a white milk or chalky appearance on top. If the floor is wet, it returns to the dark color it’s intended to be. Once dry the coating is again milky white. What has caused this to happen and how can it be corrected?
- Hi Shelby. You did you a polyurethane coating for concrete and not wood furniture or wood floors correct? If you used the correct product, then what you are most likely experiencing is a waxy substance called amine blush. This occurs if the humidity is too high or moisture settles on the surface while curing. Most of the time it can be removed with a warm soapy water solution and a soft scrub pad. Rinse well and then dry.
- Hi I have a barn I’m converting to an artist studio which will be using acids for etching in one room it’s possible some moisture may come up through the floor but there’s not any sign of that in the last year It would also be great to be a light colour to reflect the light possibly a light grey Any suggestions would be helpful Thanks Craig
- Hi Craig. If you are looking for good light reflection, then you definitely want to use lighter toned colors. The clear coat is going to have the most impact though. The high gloss topical sealers will provide the most light reflection overall.
- Hello! We have an older detached non-heated garage with a concrete floor that has some cracking, pitting (a couple deep ones!) and moisture issues. What would you recommend as the best method to resurrect and seal/finish the floor, that will fix the damage and prevent future moisture issues, and provide a durable surface for our Canadian winters (extensive freezing/thawing, lots of salt and slush off the cars)? Thanks so much.
- Hi Sarah. The moisture issue from water under the slab is going to rule out coatings unless you are willing to spend the money to aggressively grind the surface to apply an epoxy moisture vapor barrier primer first. We would recommend repairing the pitting with a polymer-modified concrete repair material. This type of repair material is much less susceptible to freeze thaw damage. We have an article here for that. In addition, you will want to fill cracks with the proper crack repair product. We have an article here for that. After the repairs are made, you will want to apply a densifier with siliconate sealer added. This will help to protect the concrete surface from further damage. Lastly, the best floor covering for this situation (if a coating is ruled out) would be interlocking garage floor tiles. These will allow air circulation under the tiles and moisture vapor from under the slab to circulate and evaporate. We have an article here about choosing tiles for winter weather.
- I have a 30 year old concrete floor that I covered when new with an epoxy paint from Sears. As best I recall it was not a two-part paint. The surface is worn through in spots and is oil-stained. I want to refinish it. It’s a working garage that will see action from floor jacks, engine hoist, jack stands and a lift. And with two old Austin-Healeys stored there it’s going to see fluid leaks. Oh, it’s in New England with salt dripping off the daily driver. The choices in flooring are dizzying. It’s not a show garage, just needs to look decent and clean up well. I’m thinking a grind and seal might be best for my needs. What do you think? Recommendations for prep and product would be appreciated.
- Hi Rick. Grinding is certainly the best way to remove the paint and prep the concrete surface for the correct profile. If you want something that is going to protect the concrete from oil stains, automotive fluids, road salts and etc, then a film forming sealer (coating) would be required. The first that comes to mind based on your requirements would be a product called HellFire. You can read about it here. This is a commercial quality product that would last many years. Another option would be one coat of a clear or colored single-part polyurea applied at a coverage rate of 200 square feet per gallon. We discuss single-part polyureas here. Garage Flooring LLC has a good single coat kit.
- Hello- I have a concrete garage floor from the 1950’s that does not have a moisture barrier in the concrete; consequently, it sweats. I want to build an office on it. How do I prepare the concrete? Please include the primer name and epoxy names. Do I need industrial strength moisture barriers. Can I build on this concrete?
- Hi Jo Lynn. Concrete sweating is from relatively warmer and more humid air that comes in contact with a relatively cooler slab that is below the dew point. The result is condensation, AKA sweating. I suggest you read our article here about concrete sweating and our article here about moisture testing concrete. You need to first determine what condition you have before deciding on how to tackle your flooring solution. Is your goal to apply a garage floor coating system?
- I need to mitigate the moisture issue in the concrete from not having a moisture barrier put in the concrete when it was poured in 1952. Is epoxy the answer or a penetration sealer, like Bone Dry? Or is zNone Dry a penetrating sealer? I plan to build an office in this garage space but I am getting nervous about all the research I have done. It is confusing to know which product will mitigate the problem.
- I think you may be missing the point, Jo Lynn. Just because there is not a moisture barrier, it does not necessarily mean that you have a moisture issue below the slab. Very few garage floors are poured with a moisture barrier in place and a good majority do not have moisture issues. Moisture barriers are more common for basements. Have you actually determined that the wet concrete at the surface is due to moisture from below the slab and not from concrete sweating as you stated? That is why I left the links in the previous comments for you to read. It’s not uncommon for people to confuse the two. Once you properly know where the moisture is coming from (above from sweating or below from moisture), then you can make a determination about how to tackle the issue based on the flooring you plan to use. You didn’t answer that questions from the previous post.
- A moisture blocking epoxy primer or other penetrating sealers are not required if the surface moisture is from concrete sweating. Sweating typically occurs in the spring and fall, but can happen any time of the year if the conditions are right. In addition, if it is indeed moisture from below the slab, you have to first determine what the moisture vapor emission rate is. This is expressed in lbs. per 24 hours per 1000 square feet. This number will determine if a moisture vapor blocking epoxy primer can be used and what kind. This requires proper testing with a couple of calcium chloride kits during the periods when moisture is present. Penetrating sealers such as Bone Dry and etc. are not very effective depending on the flooring you want. Also, the marketing information you read about products can make things confusing.
- So to restate; you need to first determine exactly what type of moisture issue you have. Test for how much if it’s moisture from below the slab. Then let us know what was determined and what flooring you had in mind and we will be happy to help you figure things out.
- Hi! We live in Oakland, CA (so 2/3 dry season, 1/3 wet season) and have a semi-below grade garage. According to the preexisting efflorescence and spalling patterns, the poured concrete walls get a decent amount of hydrostatic pressure, especially on the uphill wall (makes sense...). We recently had the walls and floor repaired/refinished – Sakrete high strength was used for repairs and patching, and everything was coated twice with Ardex cd fine. So...for the hydrostatic pressure reasons, I was leaning towards using a penetrating sealer... something like a RadonSeal or foundation armor sx5000 WB (waterbased), but am having a hard time getting a confident answer regarding using these products with a polymer-infused concrete product like Ardex cd fine (whose tech sheet states to use a “waterborne, breathable concrete sealer”). Should one or both of those sealers be fine with the Ardex? If not, what would be a better sealant option (barring exterior water mitigation...we got some quotes, and the cost/benefit ratio too high for such a tiny, minimally usable space). Thanks in advance for any guidance...
- Hi Seth. Penetrating sealers do not work as they should when polymer-modified products are introduced. The reason is that these sealers have a reaction with the minerals in the concrete. This reaction is what produces a gel like material that performs the sealing. Regardless, they can only work so well when trying to mitigate moisture from the inside out. The best way to stop hydrostatic pressure is from the outside in. What we would recommend doing instead is to apply a moisture blocking paint by DryLoc. Something like this here would be an example. You can give their tech line a call to discuss. Something like this is going to have a better effect on the repaired areas since a penetrating sealer will not react as it should.
- Hi there. We have a detached garage that is 6 years old. I recently decided to use half of it for a home gym and upon cleaning it, realized that we have a dust/efflorescence problem. Knowing our builders, and from my research on this, I assume it was not the ideal concrete mix. We live in Georgia and it does rain fairly often (depending on the time of year). I was planning on purchasing the PS104 Lithium Silicate Densifying WB Penetrating Sealer w/ Siliconate Repellent that you’ve previsouly recommended but I also saw another article where an MMA acrylic was recommended. 1) Which one is needed to solve the dust problem? and 2) Do I need to do a moisture test? If we have a lot of moisture does that mean that no sealant will help?
- Hi Caitlin. If the garage slab is below grade or has shown signs of efflorescence or any wet spots, then you should do a moisture test first. Densifiers will do a good job with dusting concrete if it’s a light dusting problem. If the dusting is more than light, then an acrylic coating sealer such as an MMA like this one here would be a better choice.
- Thank you. The garage is above grade and with no wet spots. I’d say the dusting is more than light, but I don’t have a comparison, it is just my opinion. Question about the moisture test... what exactly is the point of it? For example, if the test shows that there is a lot of moisture, then what? Thank you!
- The moisture test is to determine if there is moisture under the slab that the concrete is wicking to the surface. Such moisture is not good for coating and can cause them to delaminate. If moisture is an issue, then special moisture vapor blocking epoxy primers must be used for coatings.
- I am debating between using an acrylic concrete sealer vs epoxy. I am cost concious and would like the cheapest option.
- But the following is what I need to achieve: the garage is dusty and has oil marks from cars parked in here. We want the floor to look like the picture above of acrylic sealer. But it should be easy to clean off any oil spills etc and should be smooth to the feet and not be dusty (looks for legs to be clean even after waking on it all day).
- Also, I am thinking we would grind the floor before putting the sealer or epoxy (so we can remove all the dirt etc). If we plan to use a acrylic sealer would not recommend we mechanically grind?
- Hello Sri. Acrylic sealers do not compare to the performance of epoxy. The best acrylics are solvent-based and if I remember correctly, you were not keen to using a solvent-based product. This would mean that you would need to use a water-based acrylic which does not perform well in a garage environment, particularly with chemicals. Oil will usually come off, but if you ever spilled gas, brake fluid, or any other caustic chemical on it, it will soften and smear. If you like the look of the floor above, then we would recommend using a clear epoxy. Yes, you should definitely grind the concrete in your case. Dusting is caused by a fine layer of weak concrete. Etching will not remove this layer, but grinding in most cases will.
- One final question: is the pain delta between the water based epoxy (say Shield Crete with ~ 50% solids) and solvent based (say shield Crete XL with ~ 100% solids) the solids %?
- Does it mean that we get a somewhat similar quality of expoxy on the floor (wrt durability etc) with 2 coats of the diy water based as with 1 coat of solvent based?
- You are comparing apples and oranges. Two coats of a residential quality, low solids water-based epoxy coating does not double its performance or make it somewhat comparable to one coat of a 98% solids (+/-2%) commercial quality coating. Shield Crete XL is a low VOC coating that has a very small amount of solvent added to the part-B hardener to make the coating easier to work with. One coat of Shield Crete XL applied at the minimum recommended coverage rate will be three times thicker than one coat of the water-based Shield Crete (no, three coats of water-based will not equal the performance). The high solids epoxy is a different formulation that has a much higher abrasion rating for longer wear, it’s much more glossy, it will not incur hot tire pickup when installed correctly, and it will withstand chemicals better.
- Two coats of the water-based epoxy will help resist hot tire pickup a little better, but it will not improve the wear rate or resistance to chemicals. When it comes to coatings, you really do get what you pay for. Doubling up on inexpensive does not raise the quality of the coating.
- Hi, I have a new garage that I am looking for the proper coating/sealing approach for. It wll be used for persoal vehicle repair/maintenance/restoration. I have experience with epoxy primer/urethane top coat systems via parking deck rehab. However, I am also aware of the high degree of difficulty and cost associated with these systems. I am trying to determine a sealer/coating that will provide oil and other auto type fluid protection against penetrating but also good non-slip protection, and throw in cost savings as well if possible. Aesthetics are not high on my list of concern.
- Hi Geo. You might be a good candidate for HellFire Coating. It would definitely meet your goals. You can read about it here. It is not as slippery when wet as other coatings, but you can add anti-slip media into the final coat if you like.
- Just finished a new garage. Need to seal it and would like to have a bit of shine to make it easy to clean, but not overly slick when wet. Need something economical. What are my best options. Due to the size the of pour I need a choice that is less than $1/sq if possible.
- Hi Rick. You may be a good candidate for a product called TS210 by Concrete Sealers USA. It will easily fit within your budget. You can read about it here. Two coats will provide a thin, but very tough and stain resistant finish that is a breeze to keep clean.
- Hello, we just had our garage floor done by a “professional”. We wanted it red, white, and blue. He first prepared then painted the floor with white epoxy base and spread red and blue chips in a medium coverage. He then used a top coat. We were not happy with the uneven coverage and the floor felt very rough. He came back and spread another clear coat of epoxy and did a full coverage of red, white, and blue chips. The next day (yesterday) he spread another top coat. It looks much, much better. However, I can still feel the flakes and even see some edges curling up as I rub my hand over them. Can another top coat or even 2 be applied? Do I need to do anything in-between coats?
- Hi Joyce. Full color flake coverage is rarely going to be real smooth. It can have a heavy texture to a light texture depending on a few factors. Did the installer scrape all the flakes real well before applying the clear coat? What type of clear coats have been applied? If you want to be able to coat over the flakes as much as possible to achieve a smoother finish, then it would require a 100% solids clear epoxy. A 100% solids epoxy applied at a low coverage rate goes on real thick and self-levels over the flakes and will not shrink in thickness as it cures. What you see when wet is what you get when it cures. Lower solids epoxy has solvents or water that evaporates once applied. This causes the coating thickness to shrink and expose irregularities. It you want a real smooth finish, we would recommend going over the entire surface with a floor maintainer and 100 grit sanding screen. Sweep / vacuum, wipe down with denatured alcohol, and then apply a 100% solids epoxy at a coverage rate of 125 – 150 square feet per gallon.
- OK, that makes sense then, Joyce. Polyurethanes are excellent wearing clear coats, but they also are very thin. They are not the best coating to use if you want a much smoother finish over a full color flake surface. It would be a good choice to apply over the clear 100% solids epoxy if you like.
- All Garage Floors is the most comprehensive resource on garage flooring that you can find today. We are here to help you with the latest information about garage floor coatings, garage tiles, floor paint, garage floor mats, concrete sealers, and more.
- We are a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for us to earn fees by linking to Amazon.com and affiliated sites.
- Have a question or submission? Just let us know here! Proud of your own project? Just send us your project info for consideration to be displayed on our Reader’s Projects page.
- This website uses cookies for the best browsing experience. By continuing to use this site, you accept our Cookie Policy OK, Got It!
- This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
- Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
- Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
Title:How to Paint Concrete In 5 Steps
Passages:
- Painting concrete surfaces requires more skill, tools, and time than throwing a coat on drywall. Here’s how to do it right.
- While you can paint drywall in a day or two, you’ll need a week or more to finish painting concrete. Continue reading below for tips -- plus costs -- on how to paint concrete surfaces:
- 1. Remove dirt and grease with trisodium phosphate ($6.30 per quart concentrate), or choose a more Earth-friendly cleaner like Krud Kutter’s pre- paint cleaner ($10 for 32 ounces).
- 2. Yank off vines and moss growing on the foundation. Use a pressure washer to finish off remaining roots and dirt.
- 3. Remove efflorescence, a white powder that forms on moist concrete. Try Krud Kutter Concrete Clean & Etch ($8.50 for 32 ounces); if you need more cleaning muscle, try phosphoric acid masonry cleaner ($27 per gallon).
- Strip peeling or blistering paint indoors with a wire brush ($3 to $5), a paint scraper ($10 to $20), and lots of elbow grease.
- Water moves easily through porous concrete, so sealing interior walls is necessary to prevent moisture from seeping in, promoting mold growth and that cold, damp basement feel. Use a masonry sealer, such as ThoroSeal, that also patches cracks ($35 for a 50-pound bag).
- Carefully follow directions for mixing, applying, and curing the sealer. ThoroSeal, for example, requires two coats; the manufacturer recommends curing for five to seven days before applying the second coat.
- Concrete primer, called block primer, fills pores and evens out the surface. For exterior foundations and walls, use exterior-grade block filler, such as Behr’s Concrete and Masonry Bonding Primer, which also is good for interior concrete ($17.98 per gallon). Primer dries in two hours; wait at least eight hours, but no more than 30 days, to paint.
- Masonry paint (also called elastomeric paint or elastomeric wall coating) is a good choice for concrete painting because it contains binders that contract and expand with the concrete. Exterior house paint can crack and peel on concrete.
- Masonry paint ($20 per gallon) can be tinted and is much thicker than exterior paint. Apply it with a masonry brush ($5 to $8), a high-capacity (3/4-inch or higher) roller, or a texture roller ($5.50).
- Some masonry paint is thicker than exterior paint and contains fine particles that can clog air sprayers. If you want to spray-paint cement, ask your local paint store for a product that will work well in a sprayer ($300).
- No matter how you apply paint, let it dry for a day between coats. You’ll probably need two to three coats, so check the long-range weather forecast before you begin.
- Pat Curry is a former senior editor at "Builder," the official magazine of the National Association of Home Builders, and a frequent contributor to real estate and home-building publications.
Instance example 2
Article ID: 1366001
Question: How To Dry Figs
Answer: To dry figs, start by cutting them in half with a knife. Then, place the figs on an oven-safe rack with ventilation holes so the cut sides are facing up. Next, set your oven to the lowest temperature setting and put the figs inside of it. Let the figs dry in the oven with the door propped open for up to 36 hours. Once the figs are dry, let them cool completely before serving or storing them for later.
Related Document URLs:
- Drying Fruit by Oven or Sun with DIY Plans for a Homemade Fruit Dryer
- How To Dehydrate Fresh Figs
- Gardening Central
- How to Dry Figs in the Sun
- Take Advantage Of A Bounty Of Figs: Dry Them!
Split: test
Cluster: -1
Related Document Content:
Title:Drying Fruit by Oven or Sun with DIY Plans for a Homemade Fruit Dryer
Passages:
- Drying fruit and drying tomatoes. Instructions for solar drying and oven drying plus plans to build your own homemade fruit dryer.
- Drying food such as fruit and vegetables to keep for later use is one of the oldest and most simple ways of preserving food. So when you have a glut of your fruit this season think about drying them as well as bottling and making jams and jellies. Dried fruit can easily be reconstituted with boiling water and left to stand overnight. In the morning they can then be stewed and served with yogurt for breakfast, or you can dry your fruit for trails and camping. The only downside to drying fruit and vegetables is that you can really only dry small quantities at a time.
- Drying fruit equipment is very simple as you can see below. There really isn't anything here that you couldn't find in your kitchen.
- Drying Fruit Trays: A slatted wooden tray or some non-ferrous cake racks are suitable. If you are drying the fruit in the oven, the oven shelves can be used.
- Cloth: A few pieces of muslin or cheesecloth will be needed to come between the fruit and the trays. The more open-weaved the cloth is, the better it is for air-circulation to occur.
- Heat and Air: The fruit will need to be dried in hot, well-ventilated conditions. If this does not occur you run the risk of you fruit spoiling with mold.
- Of course the sun is what our ancestors used before modern conveniences and it works well as long as you take some things into consideration. Firstly, for sun drying fruit, make sure that your fruit is covered with muslin or cheesecloth so that you don't have flies laying their eggs in the fruit.
- Secondly, when sun drying fruit you should only dry the fruit on sunny days, that don't have a chance of a downpour of rain. Summer is by far the best time of year to do this.
- You can use your oven to dry fruit. Most types of ovens are fine for oven fruit drying; electric, solid-fuel or gas will all work.
- The ideal temperature you should be aiming for is between 49°C (120°F) and 66°C (150°F). With such a wide temperature available, most fruit drying ends successfully.
- I have had fun this winter spending time peeling and coring apples, slicing them into rings and then threading them on a bamboo stick and then drying them in front of the fireplace.
- I place the apple slices in lemon water while I am peeling them all, so they don't turn brown while waiting. If the rings aren't completely dry the first night, I just place them back in front of the fireplace a second night. It never takes more than 2 nights to dry, and they are still lovely and chewy - just how I like them!
- To prepare stone fruit for drying, such as peaches and apricots they must be cut in half and then remove the stones. Lie them down, cut side up on the trays, being careful that they are not touching to allow adequate circulation.
- Drying Figs. Figs are not cut, but left whole. Place them bottoms down on the trays. They can be flattened with the palm of one's hand as they start to dry, pressing them flat from the center down.
- Drying Grapes. Grapes can be dried either on the bunch or off, depending on what taste you want to achieve. If you remove all the grapes from the stalks you will end up with raisins or sultanas that are slightly more dry than those you can buy commercially.
- If you leave the grapes on the stalks and dry them on the bunches, you will end up with a very yummy grape that is almost alcoholic in taste.
- Drying Apples. With apples they need to be peeled and cored, and then sliced into rings. Don't worry about your apple rings turning brown. This is perfectly normal and is only a visual problem, not a problem with the drying process. The only reason why you see snow-white apple rings in commercial sales is because they have been heavily doused with sulphur-dioxide.
- Drying Tomatoes. Tomatoes have been dried in the open sun for centuries in Italy. Packed with flavor and taste, if they are dried correctly they are great to use in salads and Italian dishes. Successfully dried tomatoes will still be fairly soft, those not so will be like shoe leather and about as interesting to taste!
- Choose firm ripe Roma tomatoes as these are not as watery as other tomato varieties. Dip the tomatoes in boiling water and then ice water and then dry, core and slice lengthways. Sprinkle with a little salt. Place on racks covered with muslin and protect from insects. Dry over several consecutive days on a summers day where the temperatures are about 29°C /85°F. with a relatively low humidity. You will know when they are dry when they are slightly chewy before the leather stage!
- Place in a freezer for 48 hours to kill any insect eggs that might have gotten into your tomatoes. The pack in bottles of olive oil.
- The best tip in the drying fruit process is to make sure that you only use the best fruit that has been tree-ripened. Discard any fruit that has been eaten or stung by insects. Any fruit that is overripe will not dry successfully.
- Make sure that all drying racks are covered with your cloth of choice and place your fruit in a single layer, without touching on the racks. Cover again with your cloth if you are putting them outside.
- If you are placing them in the oven, place on a single layer, without touching on your oven racks, without the cloth of course! Set your oven on its lowest setting.
- It is quite possible when drying fruit that your fruit will take as long as 6 hours to dry if you are doing apples, and longer if you are doing apricots or peaches, even up to 24 hours for peaches. But if you are doing something small, like grapes, they won't take very long at all. Leave the door open slightly if you can't get the temperature down.
- This is something to remember, even if you are drying fruit in the sun. If you expose the fruit to direct sunlight, they will cook, turn a dark colour and be quite 'jammy' in taste. Therefore any fruit dried outside should be shaded for best results.
- This can be achieved with either a purpose-built dryer or you can modify a bookcase for your drying needs. We have plans for a homemade food dryer here. Fruit Dryer Plans.
- Allowing for plenty of air-circulation is important for successful fruit drying. If not, you will end up with mould on your fruit which will then have to be thrown away.
- Finally, when drying fruit look out for insects and ants. Insects can lay eggs in the fruit while it is drying which will result in worms hatching at a later stage.
- You can sort the ant problem out more readily by placing the legs of your dryer in containers of water on all four sides. Ants can't swim and water will make it impossible for them to crawl to your fruit.
- Drying fruit slowly really is important for a good result, so don't rush things. It can take days before your fruit dries, it really depends on the type of fruit you are drying and the water content of each. Some dry faster than others. So when you are drying it is best to place the same type of fruit on each rack, rather than mixing different types of fruit together.
- You will know when you fruit is ready when most of the moisture has been removed. If you remove your fruit too early, it will spoil. Once you are happy with the state of your fruit let it cool down for several hours before storing it.
- You can store your dried fruit in brown paper bags with the top loosely folded over. This allows the fruit to store without spoiling. You can also place them dark jar, stored in a dark place, but the lids should be loose, not tight. If you do place them in air-tight containers then the fruit has to be eaten fairly quickly.
- You may also be interested on our other sections on fruit. We have a section on planting and pruning fruit trees, as well as a section on pests and diseases of fruit trees.
Title:How To Dehydrate Fresh Figs
Passages:
- Dehydrating fresh figs is a great way to store them if you want to avoid extra sugar. Dried figs make a wonderful snack and you can either quarter or half the figs, or dehydrate them whole!
- With 2 large fig trees on our property, we end up with several hundred pounds of fresh figs each summer. We eat them fresh, can them whole, dehydrate them, and freeze them.
- Basically, we live on figs for a month around June each year! The fig tree below is just one of our trees (the other one is the same size) and it's over 30 feet tall!
- Last summer I talked about putting up fruit (strawberries) by canning them, but what about that fruit that you want to preserve without sugar?
- That's where dehydrating comes in! It's a fast and easy way to preserve fruit so that you can keep enjoying it for weeks, months, and even years to come!
- Figs are a great fruit to start with if you've never dried any fruit before, because they are fairly forgiving. You can taste test as they dry so that you can find the perfect dry time for your preferences.
- You can also just half them or leave them whole. I like to do some of each, since I like them for different things!
- I use an Excalibur 5 Tray. I've had it for about 8 years and have used it for MANY hours... it's absolutely fabulous and you should get one!
- I live in a very humid climate and it took about 8 hours for the quartered figs to be fully dry, and about 12 for the whole figs to be at the point where we like them. But times may vary, so check them every so often after about 6 hours.
- To determine where you like them, you can test them by removing one, letting it cool a bit before tasting it in all it's figgy goodness!
- If you cut them into quarters or halves, they should be good for 1-2 years in a cool dry place. Whole figs don't last that long, because less of the moisture was removed.
- I usually try to eat whole figs within a month or two, but just like with prunes, be sure to check them for mold if you pull them out of the pantry after a long stay.
- There are many different fig recipes that we enjoy for fresh figs, or even canned figs. But for the dried figs, we eat them in a few different ways.
- Whole, you can eat them like dried apricots or prunes. Halved, you can make a delicious trail mix, and quartered they make a lovely addition to a fresh summer salad with homemade ranch dressing.
- Check the figs after 6 hours by removing one from the dehydrator and allowing it to cool for 10-15 minutes before eating. If they need more time, continue to run the dehydrator and check them again every few hours until done.
- Store in an airtight container. If you cut them into quarters or halves, they should be good for 1-2 years in a cool dry place. Whole figs needs to be eaten within 2 months, at most.
- Can anyone tell me if you have to put parchment paper on your trays. This is my first time and had no directions with my hydrator. Does any liquid drain as I don’t see where it would drain. Help!!
- No parchment is needed for these figs, but for some things you might want parchment. Put the skins side down and they will be fine.
- Hi there! I’m Victoria – a work at home mom to an active 4 year old, homesteader, from scratch chef, and full time blogger!
- Here you will find delicious real food recipes, canning and gardening help, frugal living tips, and more! Learn more about our story here!
Title:Gardening Central
Passages:
- If you are one of those people who just happens to have a fig tree in the backyard, you might have wondered what it would be like to dry figs. It is not a complicated process at all, and if you just follow the instructions in this article you can learn some tips on how to dry figs the right way, as well as some other preservation techniques.
- The only way to tell for sure if figs are ripe is when they drop to the ground. Pick them all up, wash and dry them off and cut the figs in half. Next, place them on some sort of solid surface for drying. This might be cooling racks, a dehydrator rack, or you could even make your own rack with a wooden frame.
- The best and most efficient way to dry figs is in the sun. You need to have warm days with a breeze and it should be a little bit humid. You can put a cheesecloth or other covering over the figs to keep the bugs off. Lay the figs in a spot where they will get direct sunlight. If places are scarce, you can use the trunk or hood of a car, a picnic table, a deck, or even a roof, if you live in the city.
- It generally will take two days to dry figs. You will need to bring them in at night so that the dew does not wet them. Then place them back outside the first thing in the morning. You will know the figs are dry when the outsides are leathery but pliable in your fingers. There should be no juice inside the fig. The inside should be soft.
- For storage, you can put your dry figs in the refrigerator or in the freezer. Use appropriate food storage bags for either location. Heat the figs in your oven at temperatures in the 160-180 degree range for approximately fifteen minutes. Then place them in containers which are moisture-proof and refrigerate or freeze. Frozen figs can last up to three years in the freezer and figs can last for several months in the refrigerator.
- Drying figs in the oven is another option but, because of the amount of time involved, can be a very expensive choice. However long you spend drying them will use fuel, either electricity or gas, neither of which is cheap. For oven drying you can use a broiler pan or cake rack. Place the figs separately on a single layer and set the oven at the lowest temperature. This is usually in the 115 to 120 temperature range.
- Still, even in the oven, this temperature needs to be maintained for fifteen to twenty hours. Some people have ovens that cannot be set low enough. If that is the case, you can prop the door open to let out a little of the hot air. If you have a dehydrator, simply follow the instructions that came with the unit for drying figs.
- People are often surprised at how great dried figs taste and at all their uses. Everyone is familiar with fig cookies but most people do not have any knowledge of figs beyond that. You can add them to fruit and nut mixtures, put them in cereal, or even add figs to yogurt or any other place where fruits are used. Some people just eat the dry figs as snacks, just as they are, without any other preparation. The more you grow, the more interesting ways you will find to incorporate them into your diet.
Title:How to Dry Figs in the Sun
Passages:
- The fresh fig is pear-shaped and can be up to 8 cm high. The ripe fig can be both yellow-green or black-purple depending on the variety.
- The skin has a faint glow from the fruit sugar that is pulled out through the skin from within and acts as a preservative in the fruit. Fig contain large quantities of fruit sugar. But a large water content makes the taste of fresh figs quite different from that of dried figs. Green figs have a mild, acidic taste, while the dark varieties are more sweet in flavor.
- But as lovely as they are, freshly picked figs have a short shelf life, so it's a good idea to know what you want to use them for before you pick them. They only keep for a few days in the refrigerator.
- Of course, you can eat figs straight from the tree, but you can also make them into various products such as fig compote, fig chutney or naturally dried figs (the focus on this article).
- For centuries, the tradition of drying fruit in the sun has been a way of preserving food for the long, cold winter, and it is still common practice in the Mediterranean countries.
- Dip each fig in boiling salt water for 30 seconds and then let them dry in the kitchen on a clean tea towel.
- Use a straw or wooden barbecue sticks to skewer 5–6 figs each. If you can't live with the insects that will be attracted by the figs, use a Food Pantry Hanging Dehydrator/Dryer.
- Hang up the straws or barbecue sticks in direct sun for a couple of days for the figs to dry.
- You don't want your figs to go hard, so after a few days, move the figs from the sun to half shadow for approximately 8 days.
- The point of drying the figs in the sun is to remove water from the fruit to inhibit the growth of microorganisms. So be sure to take the figs in at night to avoid them becoming rehydrated with the morning's dew.
- If the figs are not flat enough when they are finished drying, and if they are too hard to just press flat, dip them in boiling salt water again. That way you slightly bleed up the figs, so you can press them gently into shape.
- Let the figs drip dry on a clean linen cloth and give them a few more hours in the sun.
- Keep the figs in an air-tight container. (Air will make the figs go hard as stone.) The right temperature is below 68 ̊F (20 ̊C). Under the right conditions, dried fruit will store for 12 months.
- Both fresh and dry figs have a high content of pro-vitamin A and several minerals: phosphorus, iron, calcium, potassium and magnesium.
- Drying (food) - Wikipedia, the free encyclopedia Drying is a method of food preservation that works by removing water from the food, which inhibits the growth of microorganisms and hinders quality decay. Drying food using sun and wind to prevent spoilage has been practised since ancient times.
- National Center for Home Food Preservation | How Do I? Dry To dry fruits out-of-doors hot, dry, breezy days are best. A minimum temperature of 85F is needed with higher temperatures being better. It takes several days to dry foods out-of-doors.
- According to the Old Testament, Adam and Eve covered themselves with fig leaves after the fall from grace. This tells us that the fig tree, Ficus carica, and its fruits go back a long way.
- Wild figs derived from Afghanistan and West Asia. From there, fig trees spread to the subtropical areas around the Mediterranean. The fig tree was brought to Spain and Portugal by the Arabs around 700–800 AD.
- Personally, I have loved dried figs since my Danish childhood. It simply wasn't Christmas without marzipan, clementines, nuts and dried figs!
- This content is accurate and true to the best of the author’s knowledge and is not meant to substitute for formal and individualized advice from a qualified professional.
- The videoes are just extra and I blankly admit that I haven't chekked them for a long time, as it has been ages since I was on Hubpages - in fact I don't even know if they change randomly.
- Salt is a natural preservative. The main effect of salt is that it kills microorganisms. Spores are not killed, but they can't germinate.
- A helpful article for someone like me who just bought a home with several fig trees and has no experience whatsoever with figs or what to use them for!
- Hi, i've looked at a number of other drying recipes for figs and yiurs is the only one that poaches them in saltwater. I'm just curious, what does the salt do?
- Why do i get maggots in my died figs during the drying period also how long should you leave them in full sun sun at the moment around 30c
- I don't have any experience sundrying figs in a tropical climate. However I think you are right, the humidity would be too high.
- Let's see if anybody out there has any experience with sundrying in the tropics or if they use a dehydrator....
- Thanks for this article. I'm wondering if this works in the tropics since the humidity is so high (above 60%).
Title:Take Advantage Of A Bounty Of Figs: Dry Them!
Passages:
- If you’re lucky enough to have a fig tree or if you’ve come across a good deal on fresh ones at the local market, here’s an easy way to preserve them for future use by drying.
- These make a very healthy snack and can be added to baked goods (such as cookies, muffins and cakes), in yogurt or cereals or eaten alone (I’ve included more ideas for use at the bottom of this page).
- Choose fully ripe fruit, wash to remove all dirt. Pat with a clean cotton cloth or paper towel to remove any moisture. Remove stems.
- Cut in half (or quarters if they are large). If they are less than 1.75′′ wide, they can be done whole.
- Place tray in the oven and let them slowly release their moisture in the heat (keep the oven door propped open slightly to prevent the pieces from cooking–a temperature of approximately 120°F is optimal. An open door also helps moisture escape).
- You’ll know pieces are done when they are leathery looking with no pockets of moisture yet still soft inside–squeeze them and if no syrup oozes out they’re good.
- If you’d like to try doing this outside in the sun, prepare fruit as noted above then arrange on screens or racks that will allow the air to circulate around them. Lay the trays out in the sun and cover the racks with cheesecloth to protect from insects. Bring the trays in each night to avoid collecting moisture. The process will take approximately three days when using this method.
- Storage: Keep in airtight containers or sealed plastic bags, refrigerate or freeze. Can also be kept in a cool, dark place if packaging is airtight. Watch for signs of moisture on inside of packaging...if so, refrigerate/freeze immediately to prevent mold.
- Dried figs are an excellent source of dietary fiber and rich in minerals such as potassium, iron, magnesium and calcium. They reportedly also contain superior quality antioxidants.
- Easiest way to chop into pieces? Use a pair of kitchen scissors...less sticky & less fussy! Or you can pop them in the freezer for about an hour before slicing.
- For Breakfast: Soak in hot water for a few minutes then chop and add to Greek Yogurt mixed with honey to taste (or maple syrup). Add some granola too if you like. Instead of yogurt do this with oatmeal.
- Fill a jar with the dried fruit then cover with brandy or bourbon. Add a strip of lemon or orange zest then refrigerate for 2 to 3 days. Serve the infused fruit on the side with a bit of ice cream for dessert.
- Add diced pieces to your baked goods: Muffins, carrot cake, breads, cookies. Pretty much any recipe that called for dates, dried prunes or apricots can be replaced with figs.
- Cheese Recommendations: Blue cheese, goat cheese, Feta and brie go nicely with them. Drizzle platter with honey or balsamic vinegar.
- Dip them in chocolate for a sweet treat! Slit then stuff with almonds, dip halfway into melted semi-sweet chocolate then chill before serving.
- Thanks for the neat page ! I have four fig trees, Brown Turkey and Black Mission. They sure like full sun, do well here, but hard to keep : birds, wasps, and ...away. This will be my 1st year trying to dry some. made chtney before, and Fig preserves. Thanks again, have a good Summer. – Marc
- In case you haven’t found Bird Netting- visit Lowes or maybe Home Depot. We purchased our fig tree netting at Lowes, we’re now upto 4 of the 14′ X 14′ nets to cover just the one tree. Next year I plan to make a PVC frame to attach the nets instead of using cloths pins at the seams. Problem is this one tree can reach 30′.
- thank you for the tips on drying out figs.we have moved to turkey and have lots of fruit trees around us.
- An online source of clever solutions for nearly 15 years, millions of people from around the world have turned to Tipnut looking for creative inspiration and reliable advice.
- After an extended hiatus, I’m now in the process of updating all the info/resources here on Tipnut. Things are a tad wonky atm but I hope to be back on track in the near future. Please be patient with bloopers while I tidy up.
- This website began in 2006 as a way to organize all the creative homemaking tips, crafts and notes I have collected over time. It's a one gal passion- project that has grown to feature all the cool ideas and tutorials that I've discovered on the internet (one of the most popular features visitors enjoy).
- Please join me in a crusade to encourage other bloggers from around the 'net! Leave a comment, link to a page, share goodies with friends on social media. When something inspires or is neat-to-know, please give credit by acknowledging the source. If we want great content, let's encourage it!
- This website or its third-party tools uses cookies to personalize content, ads/promotions & analyze traffic patterns to better develop useful content, navigation & overall user experience. If you're ok with this, simply click the Accept button below. ACCEPT Read More
- This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
- Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
- Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
Instance example 3
Article ID: 930014
Question: How To Convince Your Parents to Let You Spend the Night
Answer: If you want to convince your parents to let you spend the night at a friend\'s house, wait until they\'re in a good mood before you approach them. Before you pop the question, start with some details by saying something like, "My friend\'s birthday is tomorrow and she wants to have a sleepover to celebrate. Would it be okay if I spent the night at her house tomorrow?" From here, your parents will most likely ask for more details, so be sure to find out where you\'ll be staying and how much parental supervision there will be. To convince a reluctant parent, try agreeing to a specific time when you\'ll be back, so they won\'t worry as much.
Related Document URLs:
- The Right Age for a Sleepover
- How To Get Your Parents to Say Yeswellness for families
- My parents say 'no' to coed sleepovers
- Five Steps to Rebuilding Trust Between Parents and Teens
- Planning A Sleepover That Works
- Five Easy Questions: What You Should Ask Before the Sleepover
Split: train
Cluster: 633
Related Document Content:
Title:The Right Age for a Sleepover
Passages:
- This month, my 7-year-old daughter invited her friend to sleep over. Her mom, who had told me before she did not allow sleepovers, explained that she did not think the kids were ready for a sleepover until the age of 10. I then started to wonder whether there actually was a “right” age for a sleepover.
- Many kids spend nights away from mom and dad and stay with other family members, right? If they are lucky (my kids are not), they have Grandpa and Grandma around the corner to make the sleepover a very special outing. If they are even luckier, they have cousins of the same age to spend holidays and weekends with.
- But if kids have none of these, they depend on their parents’ perception of the “right” age for them to be able to sleep away from home.
- As a child, I fell into the second category. Grandpa and Grandma were not much of a thrill, but I was fortunate to have cousins with whom I had the most memorable sleepovers.
- Do you remember when you were a kid having a sleepover how at night the adults would come in to shoosh you to sleep, which only made you laugh more for no good reason at all, just out of a silly desire to stay awake all night and giggle?
- I remember the first real sleepover I ever had. It happened when I was about 13 and a friend of mine invited me to sleep at her house.
- Luckily for me, her parents were not strangers (they had a funny relationship, because my dad had crashed into my friend’s dad’s motorcycle and broke his leg, but her dad was a police officer on duty and apparently the accident was his fault, and they became good friends after that. 11 years later, our dads were still friends when I asked to stay over at her place).
- I think I cried for 2 months straight prior to being allowed my first sleepover, because my parents, despite all my begging, would not allow me to go. They were not completely heartless, though. I was actually sick at the time and had to take medication and they were very concerned about that, but I still did not like them saying “no”.
- I remember my excitement the day before I finally got my sleepover. I could not sleep that night from the excitement. When I got there, my friend’s house looked so beautiful and her parents were so nice and welcoming.
- Isn’t it funny that it was 30 years ago and I still remember every detail? I remember their house, I even remember that her mom exercised in front of us, wearing a transparent sleeping gown and I could see her red sexy underwear.
- I remember being very surprised, because I could never imagine my mom walking around with a sleeping gown in front of anyone – not even in front of us – let alone a transparent one!
- Unfortunately though, the number of sleepovers I had throughout my childhood can be counted on two hands. And after every one of them, I realized exactly how much I was missing. It was only as an adult, when I was studying education, that I actually learned about the importance of sleepovers in kids’ development (and their parents’ development too).
- A sleepover is a good way to help kids progress to the next level of their emotional intelligence. They develop a skill that no money can buy and no teacher can teach. It is one of those things everyone needs to experience on their own.
- A sleepover requires flexibility. Kids are forced to leave their comfort zone and take themselves into new territory, into the unknown. With Mom and Dad knowing the host family, a sleepover can teach the kids that they can take that risk and survive it.
- A sleepover allows kids to examine the differences between their family and the host family. Yes, it includes the risk of them finding advantages in the host family and faults in their own family, but it is a great opportunity to show them different ways of living and to talk about the choices you have made as parents in running your family. Such talks will actually increase the bond between you and your kids.
- A sleepover is a good way for kids to experience change. This is why most kids prefer to have the sleepover somewhere else, rather than invite their friends to their own house. My daughter made this point very clear when she was only 3 years old. She said, “I want to go to Ellie’s house. I can play with MY toys anytime”. Change is something kids need from time to time and a sleepover provides plenty of change.
- The younger the kids are, the more opportunities they need to stay away from their parents and still feel safe. Sleepovers are good opportunities enhance their social skills and independence. They go into a new house with a different set of rules and boundaries and they must learn to sense what those are and to get along – and most of the time they do. If, for any reason, you are called to pick them up because they miss home too much or the rules of the host family are too unfamiliar, do not be discouraged – this is just a sign they are not yet ready. Wait a month and try again.
- Inviting friends to sleepover can teach your kids to share their toys, their bed and even their mom and dad’s attention. The younger the kids, the harder it is for them to share, but if they do like to invite friends to sleep over, it is a sign that they are confident with mom and dad’s attention and are not afraid to share it.
- When parents allow their kids to sleepover at friends’ houses, they actually let go of some control that they have over their children’s life. This is not an easy task and the younger the kids, the harder it is to let go. In many ways, a kid’s sleepover is a chance for parents to develop emotionally too. If you are concerned, make sure you talk to the friend’s parents and if you want to build your confidence, first invite the parents with the child for a couple of play sessions to allow yourself to get to know their family better.
- A huge advantage for parents is a change in the atmosphere at home. When one family member is missing, the house is quiet and different. It can give you both an opportunity to do things differently and to give each other or other family members a bit more attention.
- I think the amazing thing is that whenever kids go to other houses, they are angels. In truth, because they are not aware of the other parent’s weaknesses and because they are too busy making the best of it, they use their best manners and are on their best behavior (otherwise they might not be invited anymore). When you pick up your kids from a sleepover and you hear how wonderful they were, you can learn where your own weaknesses are. I usually use the opportunity to reinforce my kid’s good behavior by telling her, “I know that you know how to behave well. Ellie’s mom told me you were wonderful”.
- If you want to have a wonderful sleepover for your kid, here are some great tips to make it work:
- Make sure you help them entertain themselves. The younger they are, the harder it is for them to keep busy and excited for a long time, so keep your eyes and ears open and gently offer your help when needed.
- When having a sleepover or sending a kid to a sleepover, it is better not to have too many kids sleeping over together. Young kids are not sophisticated enough to be able to split their attention between too many friends. So keep it small and always keep the number of kids even.
- Ask the parents about food restrictions or any other things you should know about. Kids expect the things they are used to, so the more prepared you are, the better.
- Get the parents’ contact details and give them yours. Be prepared to pick your kid up if something goes wrong. Again, do not despair, but try again in a month or so.
- Make sure your kid understands that rules do not change when he or she has guests. You can bend the rules a little, but communicate the changes to your kid clearly.
- Encourage your kids to go and invite friends and suggest that they alternate between staying over and inviting over. This way, having 4 good friends can give you a minimum of 8 different sleepovers in any year.
- Take the pressure off the kids by discussing the sleepover arrangements with the other kid’s parents. It is too stressful for kids to handle such logistics on their own.
- September 18, 2008 by Ronit Baras In: Kids / Children, Parenting Tags: beliefs, emotional intelligence, family matters, friends / friendship, kids / children, lifestyle, practical parenting / parents, projection, sleep
- I think it is very inappropriate for a child to have a sleepover before the age of about 10. You never really know people. Children can be , and are sexually assaulted by relatives but letting your child go to a sleepover with strangers, yes their friend’s parents ARE strangers, is inviting trouble. My granddaughter recently had her first sleepover. I was shocked that my son and daughter-in-law allowed this. This coming from parents who have more rules than a 5- star general and yet they let their just turned 4 year old out of their sight.
- In term of danger for kids, parents, family members and close friends are more dangerous than going to a friends house when there are other kids there and other family members.
- I personally believe that the more people are present in the place where my kids goes to sleep over, there is less risk for the kids.
- Perpetrators work alone, they look for someone weak and children, on their own, are very weak. If they are in company of other kids or other family members of the hosting kid, the risk goes down.
- Kids going to a sleep over learn different ways of living. They see different dynamics and different relationships and it is very healthy for them. Sometimes what they see is good and sometimes it is really bad and it helps them learn to appreciate what they have at home or bring home different behaviors.
- If home is open to discussing what happened and give children a safe space to share the good and the bad of what they have experienced during their sleep over, it is a growing opportunity for everyone in the house.
- It is not true that sexual assault happens only at night. Play dates are very similar, does that mean you can never leave them anywhere?
- My eldest was sensitive to dairy and she developed respiratory infection if she had some dairy. When she was 3 years old, I realized that it is better to teach her what she can and what she cannot eat than being the “food police”. I taught her to say “I can’t have this” when she want somewhere that we were not there. She was three years old. She was responsible and very healthy girl and that went on during all her schooling (in fact, has never seen a doctor for illness until she was 16 years old – for a throat infection and at the age of 26 for fever that didn’t go away within 3 days). still is very healthy and responsible. She is 32 years old now.
- It is right to teach children to assess what is right and what is wrong and call home when they feel they are not safe. Yes, True, we can’t bullet proof any potential harm, but that is true even if you just take them to the play ground and are a meter away from them.
- I can understand why it seems shocking to you that they allowed sleep over if they are so rigid with their rules. Strict rules only mean they are scared. It is wonderful they got over their fears and allowed her to experience a sleep over.
- What did you do when your son was a kid? When was the first time he went to a sleep over?
- hi, I’m 16 and I am not allowed to go to sleepovers. J am very responsible, always get top marks at school and bave never done anything wrong. I am not even allowed to go to my best friends house who lives a block away and we are family friends who have known each other for 15 years! I think the the thing that upsets me the most is that my parents think that I am like every other kid, but I’m not, and I definitely don’t wish to be. I simply ask for the opportunities to bond with my friends and be able to have the same experience, but I am not allowed to. When I turn 18 I will have a sleepover, although I hope it is not too late. I have a great group of friends whoare super understanding about my situation with my strict parents, and they try to include me whenever they can, it’s jist that sometimes I feel so sad that they all seem closer because they hang out together so much more when I’m not allowed to go. Sometimes I wobder if I should just isolate myself, because I feel as though I can’t be a real part of the group Thank you so much for your great article and for listening to everyone’s comments, I can tell that you are a great parent because you have rules, but you also allow your child to grow and develop opinions of their own. It makes me happy that at laast some childreb will have a happy upbringing. :)
- It is sad that your parents do not feel confident to allow you to sleep over. Remember, it is their lack of confidence, not yours.
- I agree with you that sleepover is an opportunity to bond and that it is sad and frustrating your parents’ fear is higher than their desire to help you bond with your friends. Remember, it is their fear, not yours.
- It is beautiful to read that you know yourself and that you know that you are responsible. Keep those thoughts. You are going to live with yourself all your life and you are the only person in the world who needs to think highly of yourself. Remember, they don’t allow you because of them, not because of you. You’re OK.
- Having such friends who are understanding, is a treasure. They are friends to keep! don’t isolate yourself. Why? Because if someone is doing something that is hurtful to you, you should not do it to yourself. Never, never , never hurt yourself for things other people do.
- Enjoy every minute with them. Be understanding if they are closer to each other. See if you can invite them over to hang around so your parents feel more confident. Invite one best friend to a sleep over. Do the best you can to keep those relationships. If they are good friend and they make you happy, enjoy it ! Soak in the time with them and don’t isolate yourself. There is a beautiful quote by Jim Rohn ” The walls we build around us to keep darkness out, also keep out the joy” Don’t put walls to prevent yourself from getting hurt, it’ll take away the beautiful thing you have with your friends now.
- Thanks for the compliment about my parenting. Your own children give you the “Award” for being a good parent. They do it when they raise their own children. When you raise your own children, just remember that sleep overs are good things and fix it in the next generation. I did! I encourage sleep overs, my parents didn’t. Nothing is too late. There is hope!
- have a code word. if i used the word ‘fantastic’ on the phone with my mom, she would come pick me up no questions asked. even if i begged to stay. that way she could take the blame for ending the sleepover, and my friend wouldn’t know i wanted to go home.
- What a great idea. I hope many readers read this and know it is possible to make sure your kids are safe. Thanks for sharing. Ronit
- I think it is. I wonder what are the circumstances behind your questions. As a mother, I ask myself, would I like my 37 year old son/ daughter to come for a sleep over from time to time and immediately I answer. Sure! Why do you ask? What is your opinion about it?
- I am an adult. Sleepovers are a cultural thing which exists in a few countries and, in my opinion, whose potential benefits are heavily outweighed by the potential risks (exposure to pornography; indecent behavior or even molestation; exposure to alcohol, drugs or smoking; or, at the very least, exposure to values, talk, and behaviors that one doesn’t deem beneficial to one’s own children (unsuitable television programs, video games, etc.)).
- In my country (Eastern European), such a thing as sleepovers didn’t exist when I grew up and I don’t think it is popular there today either. People there simply don’t like their children to sleep at other people’s houses. (That’s why I say this is a cultural thing; there are millions of people who lived without sleepovers and that was the LEAST of their concerns, really!)
- Also, I myself, as a child, wouldn’t have wished that as I only felt and feel comfortable in my own house. This doesn’t mean that I’m not independent or that I don’t have social skills or that I missed out on anything important in life. In fact, it is by NOT copying others that I managed to focus on my goals and be successful in life, even in the foreign country where I moved.
- I moved in a professional interest to a Western European country where this thing exists and I don’t see its benefits at all. In fact, it is sad and harmful that people tend to copy everything that others do, without more reasoning. Fortunately, not all people do the same.
- I also see the results of this type of habits (which involve young people spending too much time with peers): smoking and alcohol consumption at an early age, not enough focus on learning, loosing one’s innocence at an early age.
- If I think well, in fact, everything BAD that I learned in life, I learned it from peers (sometimes too early in life). And it wasn’t even during sleepovers, which I never did or wanted to do; it was during simple play without adult supervision.
- I am an educated person, postgraduate, and I have a strong conviction that sleepovers are not at all necessary and that they take away from a child’s innocence (even if you, as a parent, don’t get to know it; because most of the times you DON’T!)
- Amelia, sleepovers should be supervised by adults and parents should only send their kids to be with friends they consider to have a positive influence over their children. It’s also important to trust the host parents.
- When organized properly, sleeopvers are a wonderful opportunity for kids to experience something unusual and broaden their perception of home life, friendship and more. Don’t let fear prevent your kids from having this.
- Sleep overs have a place in helping children with their separation from the people who are close to them. Similar to them going to day care and going through some separation anxiety , the first time they sleep away from home brings fears and anxiety. Avoiding it, won’t make it go away, but only postpone the practice.
- I agree with you that we need to be wise about it and make sure our kids are very safe. This is why it is recommended for kids to do their first sleep overs with grandparents or close family members.
- Again, there is no guarantee for their safety when going to family members but the truth is that there is no guarantee for their safety when you bring a babysitter home, when you send them to a party, when they go to school or anywhere away from their parents.
- Sleep over is a step in development that kids need to experience in order for them to develop some social skills and resilience. I wrote a list of advantages to sending kids or inviting kids to sleep over at your place.
- I know that you are right about bad things happening during sleep over and it is good for parents to take it into consideration by contacting the hosting family , by teaching kids to be aware of “inappropriate things” – ( it happens to us several times that they called and asked to be picked up early because inappropriate things happened – for example, going to a birthday party at the age of 14 and the dad ( who is a good friend or ours) gave the kids alcoholic drinks. I consider any such thing as an opportunity for the kids to develop critical thinking and a good skill for life. Most of their life, they will be adults and make their own choices about what to do in gatherings when people do inappropriate things. And you can minimize the risks by hosting sleep overs. You know you can trust yourself that the kids are safe.
- I know what you mean about exposure to things that are not part of your values but that can happen just by your child going to a play time with another friend. Kids today are exposed to things that we don’t want them to see just through watching movies, looking at Magazines on the cashier in the supermarket, going on social media and having a smart phone. There is no magic in sleep overs. ( I don’t allow any device in the kids’ bedrooms so when friends are over, they can’t even take their smartphones to their rooms and most of the time they sleep over in the living room, giggle and eat popcorn) So, no, I don’t think it is a sleep over issue. I think it is connected to any ” external influences” that every parent need to address.
- I believe that practicing our social skills is important and through my work, I can tell you that there are inspiring young people who spend good quality time with each other, which I, as a parent, love to support and encourage. For that reason, whenever my kids’ friends need a hosting place for an event or get together, our house is always open. When your house is closed, they will go to anyone who opens his/her house. Safety is a priority so , sometimes kids are safer if you invite over.
- Am almost thirteen and have been banned from sleepover with a very respectable kid from school, we have been friends and known each other since grade 1, my parents know their parents very well and they get on very well but even though I am allied to other sleepovers I sm never allowed to his house.
- Look at the bright side, you can have others sleeping over. Did you ever ask your parents about this? I think having an open discussion about it, with no pressure, just a genuine question, without any intend to put pressure on them, might give you the answer you are looking for. Can you have this friend over your place? Can you spend time together until late? You can ask your parents, “What can I do that will help you feel more comfortable about me going to sleep over in my friends house?” This question has respect to the parents’s fear and might allow them to open up with the reasons for their fears.
- Sleep over is really fun but it is not the only fun way to spend with friends. Within the boundaries of your house, try to enjoy your time with your friend as much as you can.
- That is strange your mum lets your siblings sleep over and not you. Why are you doing home schooling? Is it something you want? Can your dad, who is away help in any way? It is hard to wait 2 years to go out and meet people. Do you have friends? Who do you want to go to sleep over at? Will she be Ok for you to invite a friend over? did you ask her for her reasons not to allow you to go ? My suggestion is: Ask her and wait for the answer. don’t say anything. just ask and if she doesn’t answer, stay calm and ask again. Why are you so concerned about me going to sleep over? Why do you allow my siblings to go to sleep over and not me? What do you think will happen when I am 18?
- It is sad that you are so isolated. do you have any family member ,mum’s side that can help you talk to her about it?
- Ok So Im 11 Turning 12 in 10 Dayss And I Cant Even sleepover at my cousins house i dont know what the problem is with me ill start crying once we get to bed. So My aunt said i have to spend a full weeked from friday to Sunday at her house to be able to go to disney with her. And Im in need of advice...do u think you could give me any?? Please Im Desprate. :(
- Not all children go through the separation from parents in a proper way when they are young and they react to separation badly. I’m sure you trust your aunt and it is no that you don’t feel safe. Does it happen only when you get to bed or do you feel anxious closer to bed time? Do you have challenges with bed time in your own house? Is it better if you are with someone in the room? or not? Try to sit down and examine the feeling. What are the thoughts you have when it happens. You need help to change the connection between the thought and the feeling and disconnect them. Any life coach you have around ,can help you with this.
- My mom doesnt let me sleep over to anyones house except my best friends and whenever i try to bring up the topic of having or going to a sleepover, she says “no”. I am 12 and even if I ask to go to my neighbors house to sleep over she says no, it really sucks. I have to sit at home bored out of my mind while all my friends are having fun.
- My friend is almost 14 and she’s never had a sleepover at a friend’s house. I want her to have a sleepover at my house. I’ve talked to her parents and begged them. I even gave them a persuasive essay I wrote on it for school, but they still won’t let her. It’s not like we even live that far away from each other. We live less than a mile away. Her parents can see my house from their window. We’ve known each other for about 3 or 4 years. Our families know each other very well. We’re the same gender. What else can I say to them to allow her to have a sleepover? Please help me.
- I can only imagine that the are protective and you’ll be surprised to find out that many people do not let their kids go to sleep over and they don’t even know why. I had a discussion with one of my clients. Her son is 19, daughter is 15 and they have never in their life went to sleep over. When I asked her why? she said she is afraid but don’t know why. How about you ask your parents to talk to her parents? What about you sleeping over at her place? Does that work? My daughter has a friend that she always goes to her house because her parents do not allow sleep over. It is not the best but a good compromise. Just work with what you can. Sometimes parents say “no” and they change their mind, but think that changing their mind is a weakness. We say it is like a cat, climbing so high on the tree but can’t go down. It could be the reason. The more you beg, they more they are stuck on the tree.
- My best suggestion is to ask: What can we do to help you feel better about your daughter coming/ going to sleep over? Ask and go away. Let them think. When you ask,the brain makes a shift from why not? to how yes! From time to time, ask again, no anger. “What needs to happen for you to allow me to go to sleep over at Ashley?” No anger, no pushing, just planting the question in their head. It will be fine. As long as you plan the question, their brain will find an answer.
- Don’t give up, It is worth working on. Never, never get angry and do silly things in anger, this will make things worse. Meanwhile, have dinners together, get her to come to you and go home at 10 at night and push it slowly to 11pm or 12. Ask your parents for help.
- 16 and still havent gone to a sleepover and the reason i got for not being allowed was that they think im going to go clubbing instead its sad how little trust they have for me when I havent done anything to lose it in the first place
- It is a shame. Remember it is temporary. It is a shame parents express so much distrust if it is not true. Make sure you never do anything that you know it is not right and all will be fine. One day , they will understand. sleep over is great fun but if you don’t get it, it is not the end of the world.
- None of the reasons posted actually explain why it’s the sleeping over that’s important. All of my children have gained these experiences simply by spending the day, or even a few hours, or being invited over for dinner with friend’s and their families. Our culture is so lax with allowing children to spend the night with friends and acquaintances whenever they are invited that we have sorely lost touch with our morals, values, and boundaries. I can’t even recall one sleepover as a child when we actually even slept all night, or didn’t watch horror or sexual movies or shows that my own parents never would have made me watch, or didn’t get taught something about sexuality that was perverse or way before it was age appropriate, or didn’t do something wrong that went unpunished, or didn’t sneak out, or didn’t make prank phone calls, or didn’t have to worry about something... like being made fun of or tortured if I fell asleep at a group slumber party. I HATED experiencing these things at sleepovers, and never wanted my children to have to be subjected to these things. Think twice, they are not necessary for proper development. “there is no place like home”
- sleeping together is a bonding time that cannot be replaced with hours of dinner or play time. I have been doing leadership training and can tell you that the same program, exactly the same program, done in two days, with sleeping together ( sleeping bags, lots of teachers around, boys and girls in different rooms) and done in two separate days where kids go home in the evening produces different results. I didn’t make this up. Some things you share when sleeping together cannot be shared when you sleep at home.
- I won’t let my kids go to sleep over at houses that I think they will lose touch of the family morals and values. I think sleep overs are tests, if you did a good job, they will not lose it. In fact, going to sleep over will only strengthen it.
- I make sure the sleeping over child will be with us as a family, they are not allowed to play computer games with friends and they have no TV, screen, mobile in their beds so they don’t watch any horror movies, sexual or anything else. My kids had kids sleeping over when they were 5, 10, 15 and 18 and they are always around, we see them at all time. they sit together and sing, dance, laugh, tell jokes, talk. It is beautiful to watch them. When my daughter goes to others, I tell the parents what my values are and I make sure my kids go to have fun with them. This week, I went to pick her up from a friends’s house. she spend the whole evening and morning with her friends mum and they talked the whole time. which I thought was great, to hear someone else’s perspective on life.
- I am sad to hear you had a bad experience. There is no place like home , true. This means that to appropriate it, you have to let them go sometimes. release the control and let them experience life, as is.
- I think they are important. Necessary? No! At all cost? No! It is important not to project on our children our own fears. you watched horror movies, sexual movies, and you are still OK. your kids will be fine too!
- my son just turned 6 last week and was invited to spend the night with a child in his class. I am not against sleepovers, but I am against a sleepover with this child. He is the “troublemaker” of the class and he and my son almost had a fist fight on the playground last week. His mom is also sometimes in charge of the aftercare at school and the kids are always “crazy” when I come to pick my son up when she is there. (not that way when other parents are in charge) I also do not know the parents that well except for a few short conversations at school or on field trips that we both attended. I think that I and any other parent in this situation have a substantiated reason NOT to let their child spend the night. It has nothing to do with something that has happened in MY past. It is what is happening with my son and this child in the present. It is certainly a fear though. Fear that they get in a huge fight before the sleepover is complete. I don’t want a phone call at 2 a.m. saying that my son has a bloody nose or a black eye.
- On another note, my son does have a great friend who we have done several play dates with and my husband and I have developed a wonderful relationship with his parents. It has never come up, but I would certainly feel comfortable letting my son spend the night with him.
- If I were you. I would say No as well. Giving kids an opportunity to experience sleep over cannot be done at all cost. With such children, I avoid even play time. Trusting your gut instincts is listening to your own GPS and having a safe drive. Just to make sure you son don’t think he has a problem, you can arrange a sleep over with a kid that is good for him to associate with.
- you should just let them try it, see how it works out, if it doesn’t they can always ask to go home. i had my first sleepover when i was in Pre-K, the first time, i was scared and went home, the second time, a had no problem. As long as you have a responsible, nice family, with a parent that you know well, they’ll be fine.
- I think Purple girl 206 is right! If kids have the option to go back home, they will ask to go home.
- One thing that really annoys me with my friends (We’re all thirteen) is that their parents don’t let them do anything!And i mean anything! “Wanna go see a movie?” I’ll ask-and they’ll say no because their parents think it is inappropriate. IT WAS THE MUPPETS! And I was going to have a Birthday sleepover-but they all made excuses-My parents won’t let me. My parents don’t know your parents. I’m allergic to cats (she owns a cat). It makes me angry that these parents won’t get over their kids growing up. My parents let me have my first sleepover when I was six! GROW THE HECK UP!
- That makes you a lucky girl. Maybe they have another reason not to come to the movies? Do you mean they have never seen a movie with friends?
- the age for sleepover should be 6!!! thats when i had my first sleepover! what do u think is gonna happen??!?!?!?! i turned out TOTALLY NORMAL! omg i also thought her last name was bras....awkward
- I like your answer. think of it, if every parent say ” the right age is when I went to sleep over first” so many kids will be deprived from sleep over.
- I’m a dad in my upper 40s, and my 7 year-old daughter is hosting her first birthday sleepover here at our house tomorrow night. My wife has asked me and our 9 year-old son to stay at my mother’s overnight – not because the girls need the extra bed space, but because my wife thinks it will put the other girls’ moms at ease. I find this ridiculous, and don’t know whether to be insulted or not, but I will agree, just to keep the peace. There has never been one iota of creepy behavior in my dealing with the girls or their moms, many of whom I have met before, nor do I have ANY pedophilic tendencies. As an adult male, though I guess it goes with the territory, so to speak – we’re potentially dangerous! Sheesh! What feedback do you ladies/guys have on this?
- K-man, I can understand your wife’s request and I think if I were you, I would say ” No!”. I an understand why the others mums would feel better but this is not a reason for you to leave your house. They are grown up and they have made the decision to send their girls to a sleep over. I find it hard to believe anyone asked your wife to ask you to leave. If anyone would have asked me, I would have said to them that if they think like that, maybe it is better if they don’t come to the party.
- most parents let the kids go on sleepover anytime but who am a parent should let my kids go on a sleepover they are ready and when am ready you would have to talk with them explain how your going be away from them
- I am not sure most parents do but you are right, it is important to talk to the kids about it.
- My daughter is 5 like her cousin and they want sleep overs. I’m really not sure. A lot more resposibility with other kids. I feel quite scared about it actually. It’s very daughting. I was about 7 or 8 years when I had my first with a friend accross the road but younger when it was at my grandparents. That was usually so my parents could go out not just for fun!
- I can understand the concern, especially when you have your mind set to 7-8 years old. It should be easier with cousins as the child coming to sleep over is someone you know. I think if you are scared, invite them to sleep over before sending your daughter to sleep over. In your house, you can control what they do? Ask yourself, What are you afraid of?
- thanks for sharing this. i have a soon to be 7 year old little girl. she is my only child. she had been to one sleep over and i went to the parents house ( it was my best friend who had let her sleep over) to check on her and texted her a bunch of times. i had a harder time being apart from her then she did me. she has asked a few times to have a sleep over at our house, but when i met the parents and did the play date thing, the other parents always said no. glad you put in there to have an even number of kids but a small amount. we are a military family so its hard to keep friends around and we do not live near family. i have had three sleepovers in my life and my first one was when i was 7. im just worried she will pick up bad habits from other homes too. i told my husband when she is 10 i think she and i will be ready for her to do sleepovers. after reading your article, i see if i wait that long what she will be missing out on. again thanks for sharing :)
- Aircrewmanwife1, It was brave of you to let her sleep over. It is very important for kids health and well being to be in a different house and see how it works. I think it is good for kids to see different houses and how they function. If you are confident with your parenting, the kids will learn to appreciate you and your style after they go to other kids’ house. My kids come back and say ” In this house, the kids do not clear the table, mum is doing everything ” and they talk about it as a bad thing. I am happy they go to see that it looks bad when you look at it from the outside. Many of my kids’ friends’ parents like sending them here for a sleep over. In our house, we all help preparing dinner and setting and clearing the table, and everyone takes a salad and try new things and every time they go home their parents call and say : “What have you done to my kid, he suddenly eat salad or help at home” So , no, they sometimes learn good things. They are exposed to different dynamic, it is good for them. Kids don’t pick bad habits because they are young. When she will be 10 years old, it will be the same, if her house is solid, she will learn to appreciate it, if her house is weak, she will pick up bad habits no matter how old she is. Play date is a wonderful compromise.
- All of these things can be accomplished with playdates or full day visits. I, as a mother, would be appalled if I new another parent was wearing a see through nighty with sexy red underwear in front of my child! That is extremely disrespectful. I had sleepovers as a child and a lot went on that if they didn’t I probably would be better for it. Also, I cam from an abusive home where my stepfather sexually abused me and yet, my mother knowing this, allowed my friends to sleepover. Can you imagine? You may be letting your child sleep over at a pedophile’s house and not know it. We all have this fear within us, it’s a question we struggle with all of the time “Should I let my child have sleepovers?” Maybe there is a reason for that struggle, maybe we really shouldn’t be allowing it at all. I gave into the pressures of society and went against my own feelings and what my experiences taught me, I let my oldest son have sleepovers with one particular friend, since those went ok I let him have a sleepover with another friend, only to find out he was intorduced to porn. Great! Apparently the mother let her con do whatever he wanted on the computer. Now that I have two more boys and now a daughter, we have stopped sleepovers. There is just way too much stuff that can happen at night.
- I think you can tell your kids that your experience shows that there maybe trustworthy people but not everyone is trustworthy. Remember, I didn’t see anything wrong with wearing a sexy gown. I thought it was beautiful and hoped my mum would wear such things. The problem is that you cannot protect them forever and you have to put systems in place so your kids tell you that something went wrong. Eden, our daughter went to a party at the age of 13, it was a party, not a sleep over and it was at one of our best friend’s house. Their son was her boyfriend the year before and we didn’t think it was a bad influence or anything like that. They were nice couple and we liked them a lot. It was over half an hour drive and we dropped her in, went inside, said hi, checked around ( we knew their house, had dinners together at their place couple of times) and went home, after an hour she called and said, “come pick me up!”. We have a rule, if she says something like that, we don’t question her judgment. We asked her if she is safe, she couldn’t talk much on the phone and we drove to pick her up. She said “excuse me, I don’t feel so good” and we took her home. On the way home, we discovered that our friends, the mother and the father, opened a drinking bar for the kids and drank with them alcohol to the stage of kids drunk and talking stupid.
- I can understand your concern and I know it is real and scary but I would rather teach my kids to tell me when something is wrong to allow me to protect them.
- As you say, sometimes the parent is the abuser and we cannot be with them 24 hours a day to protect them, it is better to develop in them a sensor when something is wrong and an open channel to communicate with you when someone around them is doing something wrong.
- When there is something wrong in a friends’ house, it will be wrong even during the day, during a play day. It doesn’t have to be at night.
- I know what you mean. My kids went to a camp that the organizers neglected some kids ( not mine) in such a way that it dangered their life. I told my kids they will never, never, never go to that camp with those organizers – I don’t even argue!
- If I were you, I would tell my kids that my personal experience created fears that are hard for me to ignore and I would like to protect them and that if they work together with me to reassure that they are safe, we can find an arrangement. My solution would be always to invite for sleep overs. I know that my house is safe.
- So, do you mean she allows you or not? If your mom is not decisive it usually means she is not very confident. Again, ask her ” What needs to happen for you to feel more confident about me going?” and try working with her to make her feel good and that you are safe. You will have lots and lots of parties in middle school. Talk to your mom and help her overcome this fear.
- hi my mom says i can actully sleep over at my friends house!!! and now she is saying maybe and now she saying yes again i dont no wat to do and it is a slumber party and this is the last year we will no each other were moving away from each other next year for midddle school pls help me!
- Talk to her and try to find out what bothers her. There will be many opportunities in the future for a sleep over.
- I think your suggestions are wonderful and they tell kids to understand the adult perspective, which is the problem in the first place – they are kids! they do not have the understanding that bad things may happen to them and in my opinion it is better not to say that to them. In the issue of sleep over the real players are the parents. They have an important role in giving their kids opportunities to interact in many ways, weighing the risks. As I said, playing in the playground has many risks and if you search accidents in the playground, you would probably not take your 2 year old child to the playground ever again, still, we need to get over ourselves and realize when our anxiety has taken over our common sense. Kids needs sleep over opportunities, making it safe is parents responsibility. When there is a will, there is a way! If you are not sure about them going to sleep over, invite them to sleep over. If you are afraid they will do something in their room, have a sleep over in the living room.
- Parents’concerns are real and I would not encourage them to ignore them but to address them. Saying “No” is not addressing them but pretending they do not exist.
- Here is a good article that voices many parents concerns Ronit. http://activelyaware.blogspot.com/2010/02/important-sleepover-safety-tips.html Please don’t make light of parents’ concerns. It is likely that they are quite caring and love their children very much.
- Most parents reasons for not letting their child sleep over to someone else’s house is not to make their children’s lives miserable, but because they love their children deeply and are concerned for their safety. The world is both a beautiful and scary place at times.
- If your mom doesn’t let you sleep over someone else’s house please do not be too angry with her. Do you know that she loves you? Be glad that you have a mother that loves you. One day you will be off on your own. Older. And while you may wish you had the opportunity to go to more sleep overs, hopefully you will realize that your childhood was safe and your mother loved you and was there for you.
- There are many articles over the web that will tell you what you want to hear. It is a wise idea to present them to your parents and start a dialogue with them about issues that are important to you.
- I hope the kid that wrote this had a chance to read your comment. The more they hear that their parents love them, the more they will believe and they need to believe. Thanks.
- It is surprising that a girl turning 16 still needs to fight her parents for the right to sleep over but... as I said before, fears are so strong that your age may not help with that.
- From your comment, it is easy to tell that you are a very smart girl and I am sure that if you will seek the answer, it will come.
- Your meeting idea is great. I would recommend you will use the meeting to gather information rather than tell them what you think ( they know what you think). You can tell them “I know that you love me and care for me and worried for my safety. I appreciate it very much and I want you to know that my safety is important to me too. At one stage, I will leave home and have to care for myself. sleeping over is a trial in independence. When I grow, you grow too. I need to practice taking care of myself as much as you need to practice letting go. I know it is hard but we both need to do it and the best way we can. The more time I will have to practice, the better I will get when the time comes”
- remember, do not tell them how safe you will be only ask them ” What needs to happen for you to feel safe while I sleep over?” and wait, wait, wait for the answer. Even if you have the answer, do not reply. only say, I want to take that information, think about it and find a way that would work for both of us. give yourself 2-3 days and say: ” I thought about it and I found a way that will make you feel I am safe”
- pushing is not the way to help people overcome their fears. It is scary being a parent so be understanding and acknowledge the fear and your sincere appreciation for the responsibility they take.
- tell us how the meeting went and above all – take care of yourself in such a way that your parents will never, never, never be afraid for your safety.
- While trying to do some research on how to convince my parents to sleep over, I came across your article. See, I am 15 going on 16 and I am still not considered the right age to go to my parents.
- I have tried multiple solutions to this problem. I have attempted the childish yelling and screaming route, the attempt at reasoning and my friends parents have even gone so far as to ask my parents if I could come to the cottage with them.
- Finally, I have reverted to the most mature form I could possibly think of. I am going to research a proposal and call a meeting with my parents to talk about it with legitimate points and with sources that i have found through my research.
- The only problem is that when we’ve discussed this previously, it always comes back to their completely unfounded fear of it not being “safe”. When I have tried to further unfound their fears, it makes them angrier, even when i try to assure them i am inside, and with other parents that they know have the same parenting values as them and have known for YEARS.
- I am sure you think that you can sleep over at your best friends’ house. All kids do but as I explained, there is not right age, it is all depends on the parents fears. Something made your mom think that it is not right and you need to find out what that thing is if you want to change it. I am not sure “Fair” is right here. No one ever said life is fair, if your mom is afraid of something than in her mind, she is protecting you and fairness has nothing to do with that. Here are my suggestions: 1. Send mom this article; it will make her think about this. It is not easy to let go of fears and grown ups are afraid too. 2. Find other family members that think it is Ok and ask them to talk to your mom. Sometimes when grown ups talk to each other; they come up with solutions that kids can’t. 3. Tell her: Mom, I want to talk to you about something. Find a quiet spot, when no one is around, when there is no stress and ask her without anger, just to know, “What is the worst thing that can happen if I go to sleep over?” Make sure you ask it in an honest way, and really listen to her answer. In her answer you can hear what she is worried about. 4. Some parents do not like their kids to go over to other’s houses but they are happy to invite friends for a sleep over. Ask mom if this is OK? Maybe for a while until she trusts that everything will be fine when you are going to a friends’ house, she will let you invite friends for a sleep over. 5. If mom ( or dad) are not happy, make sure that the first sleep overs are with one friend and that they talk to your friends’ parents. I am a mom and I only allow my kids to sleep over after I talked with their friends’ parents. Maybe that will help you mom too. Try not to think of it as “fair” or not. Your mom loves you very much and she may have different ideas of how to raise you. I think it is important you talk to her about it to find out what needs to happen for her to think it is Ok and help her make a different decision. I told Jess that I did my first sleep over at the age of 13. I didn’t like it but I understand my parents’ fears now so I am not angry.
- My mom said i can’t go to my “first” and “best” friend sleepover. She said I will have to be older. I read this and 3 and 4 year-olds go! And I’m ten- that’s not fair.
- I sure think that teens your age can sloop over but I have to say that I know people that something in their past makes them so scared for their kids safety that they prevent them from doing many things that seem normal and regular.
- If she lets your friend sleep over it only means she is afraid of something happening if you sleep at a friend’s house.
- 1. Send her the article. 2. Ask your friends’ parents to talk to her about you coming over to their house. Adults discussing this is different than you talking to her about it. 3. Be happy she lets you invite friends and invite them a lot. After a while she will realize that you have good friends and they do not make a mess when they visit and it is not likely to be different in their house. ( assuming it is OK when they come to visit) 4. Tell her, ” Mom, I understand you are worried. What needs to happen that for you to feel better about me going to a sleep over?” just ask. avoid fighting about it. just wait for her to answer. The question will make her think and understand that it does not work like that – one day she gets up in the morning and says, you are 14, 15 or 16 and from now it is OK to sleep over.
- Do not be angry at her. I was kid who only went to a sleep over at uncles and unties place. My first ever sleep over was at the age of 13 and I cried my heart out so they will let me sleep over ( My dad agreed because my friends’ dad was the local police officer that my dad knew personally) It wasn’t a big deal. I survived. you will too.
- My mom, she don’t alow me to go sleepover. Im like 13 now and she still don’t think Im at the right age to be at any sleepover. Whats wrong is that she let my friend sleep at my place but she dont let me sleep at other people’s place. She needa learn how to know what the other parents feel. Because I hate her for not understanding. Reading all that. I want my mom to read it as well. I just got my friend’s call asking if I could come or not. And I have to hold my breathe saying no and hung up because i was about to cry.
- The right age would be when they don’t cry when they sleepover. Hahahah. Well, maybe I’m just talking about myself :)
- Sign up to receive posts by email and get my free mini-course Seven Emails with Seven Secrets for Seven Weeks to boost your personal development
- Sign up to receive posts by email and get my free mini-course Seven Emails with Seven Secrets for Seven Weeks to boost your personal development
Title:How To Get Your Parents to Say Yeswellness for families
Passages:
- You really want to go out with friends on Friday night and you know that mom/moms/dad/dads/mom and dad aren’t going to budge. Here’s how to get them to (at least) consider:
- 1. Let them know (with advance warning) that you’d like to arrange a time to sit down and talk with them about something.
- 2. Be flexible about when you can meet. For example, don’t try to meet at 10 at night when you know he/she/they have to wake up early for work. Set a time after dinner (that you ate WITH THEM at HOME!) or when the family is just hanging out.
- 4. Sit down with your parent(s) and explain the upcoming event that you’re asking permission to attend. Important details: Who will be there, who is supervising, what will you be doing, what date/time will you need to be there and how will you get to the event, will you need money, and why you’re so excited about the event.
- Your parents may not approve of the other people who will be at the event. Good luck with that one! If your parents have reason to not approve of certain people, then this is gonna’ be a tough sell. Parents generally don’t like people who they feel puts their teen at risk.
- Your parent(s) may not believe there will be supervision. Offer to have your parents talk to the person supervising. Provide them with the (CORRECT) phone number.
- If you need extra money for the event, come to the meeting with your parent(s) with an idea of how you plan to earn the extra money at home (pick up a few more chores, mow the yard, etc.). Follow through with these chores OR IT WILL HURT YOU NEXT TIME!
- 6. If the discussion is not going anywhere, ask your parent(s) the main reason they’re saying no. Do not yell at them; this will only make them more firm in saying no. Reschedule the discussion for a later time when everyone is calm. Revisit step #1 and try again.
- Remember, your parent(s) want honesty and they want to see you handling yourself responsibly. Come to the meeting prepared to answer questions. Have answers to the tough questions and also come prepared for your parent(s) to say no. Good luck!
- Ha ha ha, Devon! You use CONTROL to force them to give you your way! Don’t hold your breath too long! 😉
- What exactly seriously inspired u to create “How To Get Your Parents to Say Yes”? I reallyreally enjoyed it! Thanks for your time ,Lucretia
- My parents always say no . And if I ask them why , they say no means no and yell at me .
- thank you i will try because i really want to go to this sleepover i dont think she knows that i am old enough yet but i will try.
- Same my parents won’t let me go on this residential trip for 3 days but I said I will pay £145.00
- I can’t wait to try this! I know my parents are going to say no,but it’s worth a try? I guess. Anyways,the thing I’m asking for is a iPod 5 (white 36g) I know that’s alot of money and everything,but you know..I think I’ve come to that kind of age when if you don’t have an iPhone or iPod or even your own bedroom your a loser.I think my parents know that I really want the iPod ‘cuz I always go on the computer and go on the apple website,and look at all the devices and the new iPod 5 features.Wish me luck! ~Aria
- lol I really hope this works! My friend asked me if I wanted to go to this convention in CA, but we both live in PA and my friend only has 4 tickets so my parents don’t get to go but maybe it will work!
- Omg I asked my parents to buy me a iphone I’ve been wanting for 2 months I did this and they said yes
- I’m so sorry! This is definitely not a miracle solution to get your parents to say YES. I hope everything turned out okay.
Title:My parents say 'no' to coed sleepovers
Passages:
- Tell your mom and dad that they are just your friends, not boyfriends! Also, it's a sleepover, and I'm sure that their parents will be supervising. Also say that you're 16, not 10.
- I'm sorry to say, but a coed sleepover is too inappropriate. Put yourself in your mom's shoes. Suppose your 16-year-old daughter comes home and says, "I'm going to a coed sleepover." Remember, she is just trying to protect you. You'll thank her in the future.
- Get more information about the sleepover. See if the boys are sleeping in the same room as the girls. They are probably trying to protect you.
- I can understand why your parents may not want you to go to a coed sleepover, but it seems innocent enough. You should find out everything you can about the party, like who will be there and if any parents will be home. You should relay what you find back to your parents ... and be honest with them! Your parents will respect your honesty more than anything. Hopefully, if you make a strong case, you and your parents will be able to compromise.
- I can understand why your parents might be hesitant about letting you go to a coed sleepover. They might be uncomfortable with it, especially if they don't know your friends well or the parents who are hosting it. However, they might give in if they become more comfortable with the entire thing. Ask if you could host a few coed sleepovers first, just so your parents can see what the whole scene is like, then maybe they'll feel more comfortable with the entire situation, and perhaps let you go to another friend's coed sleepover. However, I wouldn't push it on them. If they just aren't going to let you go, you can't force them to. There are other ways you can have fun with friends, and definitely more options you can explore besides sleeping over at each other's houses.
- This is a very compromising position you are in. You are pressured to act cool by wanting to throw a coed party. However, you can't make your parents let you go to a party or to throw one. I can understand nothing romantic is going on, and that is probably the way it will stay. Show your parents that you can have fun with a guy without throwing a party. If you can prove that you have fun with the guy by yourself, you can get along with him fine in a group. This should tell them that you are responsible and won't make any stupid mistakes. Good luck, and if you can, have fun!
- As much as you want to have a good time with your friends, coed sleepovers aren't the best thing to do. Both guys and girls have raging hormones in teenage years. Coed sleepovers can lead to games involving sexual activity. Maybe instead of spending the night at a coed sleepover, you could go for a few hours. You can also joke and laugh with your friends at school or at any other place you hang out. Since summer is coming, you and your pals could have a cookout, go swimming or go to the movies. The options are endless! I don't think everyone has coed sleepovers. Most kids I know aren't even allowed to date. So if you just want to joke with your pals, do that - just not at coed sleepovers.
- Well, you know what is going on at these sleepovers, but your parents may not, and they may not trust your friends or know them very well. If your parents were acquainted with your friends and their parents and talked to them before the sleepovers to make sure a parent would be home, then maybe they would feel more comfortable in letting you go.
- You should tell them that you are responsible and that you are old enough to make your own decisions. I'm almost 16 so I can understand how your parents don't trust you all the time, but you want them to just let you make your own mistakes. Tell them that you know the consequences of things and you aren't asking for trouble ... just a little fun!
- You just have to talk to them. Explain that you don't like any of these boys. Hopefully they will understand and either let you stay over or they will compromise with you. If this doesn't work, you have to respect your parents' wishes; they are only looking out for you.
- You shouldn't go if there isn't supervision. If there is supervision, tell your parents that, and have your parents talk to those who are supervising. If no one is supervising, your parents have the right to not let you go, because even if you are all friends, something could always happen. What if one of them brings alcohol and you all get drunk and you end up doing something you'd regret? Besides, there are other ways to have fun with your friends.
- I don't think you're going to be able to convince them, especially if they're like mine. I know for a fact that my mom will not let me sleep anywhere boys are sleeping, not now or when I'm 16. She lets me go to coed parties as long as there is an adult there (and she checks!), but she won't let me stay, and maybe that's not a bad thing. My mom feels it's just wrong for boys and girls to have sleepovers unless it's like a vacation or something and the adults are right there. Your parents are just protecting you; you never know what can happen. I'd just go to the parties and have fun, and because you're not staying over your parents might let you stay late. This way, all you're missing is the sleeping. Don't feel you're missing out; they're just looking out for their daughter.
- Sorry to say, but I really don't think at 16 you should be having boy sleepovers. There's no reason you can't hang out with your friends and then go home at curfew. I mean, what are you missing but the sleeping part, right?
- Please write your best advice in 250 words or less, and e-mail bgilhooly@th- record.com by 3 p.m. Friday, May 26, with "What Would You Do" in the subject line. Please include a photo, either by e-mail or snail mail. And if you have a suggested question for a future Question of the Week, please send it, as well.
- I'm 16, and a lot of my friends are starting to go to coed sleepovers. My parents refuse to let me go, because boys are there. But these boys are my friends, and there's nothing romantic going on. We just all want to have fun together, listen to music, joke around, stuff like that. I feel like I'm missing out on all the fun, especially this time of year, when everyone will be doing this for prom and graduation nights. How can I convince my parents to let me join in?
- I'm 15 years old, and my parents still set a bedtime for me on school nights. They let me stay up late on weekends, but insist that I need to stick to a schedule during the week. My friends get to go to sleep whenever they want to. Is a bedtime for teens too babyish?
Title:Five Steps to Rebuilding Trust Between Parents and Teens
Passages:
- Slamming doors, screaming voices, sulking faces – what does broken trust look like in your home? For many, it’s an ongoing cycle – the teen lies, breaks curfew, experiments with drugs, or gets into trouble at school. The parents respond with guilt trips, threats to take away privileges, and violations of their child’s privacy. Both sides feel trust has been broken beyond repair.
- Trust is a fundamental building block of parent-child relationships, especially as children develop into teenagers. “In general, trust is broken when a parent or teen acts in a way that doesn’t meet the other’s expectations,” explains PJ Swan, LPC, Director of Family Services at SageWalk The Wilderness School. “Both parents and teens break the other’s trust when they engage in outbursts or temper tantrums, guilt trips, or threats of any kind. Parents lose their child’s trust when they fail to set and enforce limits and when they resort to snooping or spying to learn about their child’s life.”
- Trust is a two-way street. In order to gain their parents’ trust, teens have to demonstrate a pattern of trustworthy behavior. Every time a child follows a rule or meets their parent’s expectation, the baseline trust and respect expand. “The key is remembering trust builds slowly and can be broken down easily,” Swan advises. “For every five times you do the right thing, it only takes one poor decision to undo the trust you’ve built.”
- Just as every child wants to be trusted, every parent needs to earn their child’s trust. A parent builds trust every time he treats others with respect, follows through on a commitment or promise, or stands firm in setting and enforcing boundaries. “This doesn’t necessarily mean your children will ‘like’ you or treat you like a friend,” Swan warns. “But trust has little to do with how much we like someone or their decisions. Rather, it is the firm belief in the honesty and reliability of another person. That’s what being a parent is all about – giving a child what they need, not necessarily what they want.”
- With years of experience working with families, PJ Swan has put together the following steps parents can take to rebuild trust after it has been broken.
- “Ask your child open-ended questions about what trust is, how it was broken, and what steps can be taken to rebuild those bonds,” recommends Swan. “Rather than assuming everyone knows what trust is, decide collectively on a family definition of trust, try to understand each other’s perspective, and clear up any misunderstandings up front.”
- Families should discuss the fact that trust is a two-way street and that both parent and child have responsibilities in the process of reconnecting. As the family negotiates the rules and boundaries, schedule regular meetings to discuss your progress and evaluate any setbacks.
- When parents trust their child, everyone benefits. “Since teens tend to be somewhat self-absorbed, you may need to explain the concrete ways in which a trusting relationship will benefit your child,” says Swan. For example, a teen may earn greater privileges like a later curfew, permission to drive the family car more often, more time with friends, or the freedom to go on that trip he has been planning. “By explaining how trust is relevant to him, how it can make life at home more peaceful and supportive, and how it can improve his life in general, he’s more likely to stay motivated to do the hard work.”
- Telling a child to “act her age” or “do the right thing” won’t give her the information she needs to win your trust. Instead, give her specific benchmarks that will help her meet your expectations. Explain that while behaviors like cursing, slamming doors, ignoring homework assignments, and talking back will diminish trust, behaviors like finishing chores on time, getting good grades, and calling to check in at a designated time will increase trust.
- When your child meets your expectations, verbally reinforce those positive behaviors by acknowledging her efforts. Show your appreciation with a simple “thank you” or pat on the back, and offer additional privileges and rewards as she becomes more trustworthy. By giving positive feedback, your child sees that you, the parent, are willing to do the work, and she will feel encouraged to behave responsibly.
- Remember, there will always be bumps in the road to rebuilding trust. The family may be making progress and suddenly something happens to break trust down again. The ups and downs are all important parts of the process, and even small failures can result in stronger bonds. “Sometimes teens need to take one step back before taking the next step forward,” says Swan. “For the family’s sake, both parents and teens need to be willing to try and try again.”
- Parents are in the best position to know what’s right for their children. Even if both parent and child are working hard to rebuild trust, both parties must set reasonable expectations of themselves and others. Trust grows slowly, piece by piece, with every good decision that is made.
- “Trust-building is not an end in and of itself,” says Swan. “It is an ongoing process of renegotiation and personal and collective growth that is required in every relationship. With communication, patience, and a little faith, you can replace past hurts with loving bonds and hope for a more fulfilling relationship.”
Title:Planning A Sleepover That Works
Passages:
- “Psssst. Mommy! Brenley can’t sleep and misses her mom and dad real bad and wants to go home. Are you awake?? Mommy!” My 9 year old was hissing this message of doom in my ear. At 2:30 am. That’s right people, 2:30 am. After failing in my negotiations to get her friend back to bed until a decent hour, my husband had to get dressed and drive her home. Did I mention that it was 2:30 in the morning?
- Sleepovers can be great fun for kids and offer a chance to play far longer than the normal playdate, but when they go wrong—they tend to go really wrong. If your child has been invited to participate in a sleepover at another child’s house, here is a iMOM’s Sleepover Strategy that Works for some ways to make sure it’s a good experience.
- You want your children to come home after a night out, so you can check for signs of drinking or drug use.
- Note: Even if your kids go out for prom or homecoming with friends, require them to still spend the night at home.
- If you sense that your child doesn’t want to go, or you think she’s just not ready, tell your child, “You can tell your friend I said no.”
- If “everyone” is going to a sleepover, and your child doesn’t want to go, or you don’t want her to go, come up with a fun alternative: invite friends over, ask your child’s grandparents to do something with them, or do something exciting as a family.
- Try to expand your child’s friendship circle beyond his school. Encourage him to make friends with kids through sports, church or other activities. That way, if “all” of the kids in his class are going to the sleepover, he’ll have other friends to spend time with.
- Do talk about what movies you let your kids watch. Say something like, “We made a decision as a family to stick with G-rated movies.”
- Don’t micromanage. It’s not polite to insist on certain bedtimes, food choices or activities. If you must be in control of these, have the sleepover at your house.
- These three questions will help you assess if your child is content to stay the night, or needs to come home. Since each is a “Yes.” or “No.” question, your child won’t feel put on the spot in front of the other parents.
- If your child indicates that she wants to come home, ask her to put the other mother on the phone. Then, say something like this, “Hi, you know, Megan isn’t feeling well, so I’m going to head over and pick her up.”
- You can set a late-night pick-up so your child can have an “almost sleepover,” or you can head right over to pick up your child.
Title:Five Easy Questions: What You Should Ask Before the Sleepover
Passages:
- There were few things I treasured more than spending an overnight (they weren’t called “sleepovers” in those days) at the home of close family friends. After all, I’d practically grown up alongside their daughter. Together, we’d enjoyed beach days, tree-climbing expeditions and countless games of tetherball. We’d shared overnights since we were 4. I loved them.
- What I didn’t love was the shouting — no, make that screaming — that often reverberated throughout that house. Yelling. Swearing. Slamming. Scenes enacted between the mom and dad; the mom and older sister; the two sisters.
- With little basis for comparison (maybe other families behave like this?), I don’t remember mentioning these incidents to my own parents. I had no clue that the emotions I sometimes felt watching this — fear, confusion, discomfort — meant that something might have been very wrong in that home.
- As a young parent, I often wondered whether my own children ever witnessed episodes of turmoil, dysfunction or worse in other people’s homes. Yet, I don’t remember asking them the simple question: “While you were over at Jess’ or Bobby’s or Emily’s house, did everyone get along?”
- I also don’t recall inquiring about the kinds of things parents think much longer and harder about today. Who’s watching the kids? Are drugs or alcohol within reach? Who’s sleeping where?
- Now, older and wiser, I know better. I get that things can happen in other houses; that different families have different rules, and these rules might not mesh with our own. And that it’s OK — actually essential — that we address those differences and make “sleepover” decisions based on how well we know the friend’s parents and whether we’ve seen them interact with their kids and with each other.
- Most of all, we need to decide which questions we’ll ask other parents before allowing our child to spend the night in their home — and how we’ll evaluate their answers.
- 1. Is there a gun in your home? This one’s a no-brainer. According to a Rand report, 34 percent of children in the United States live in homes with at least one firearm. In 69 percent of homes with firearms and children, more than one firearm is present. In 9 percent of homes with children and guns, at least one of the weapons is stored unlocked and loaded.
- Yet, many parents, quick to ask about curfews, supervision and whether there are enough booster seats in the Volvo, often breeze right past the gun issue, even though, according to The Center to Prevent Youth Violence, 1,600 gun- related youth deaths result every year from kids having access to firearms in homes.
- 2. Who’s watching the kids? Chances are, you spend time and effort vetting the baby-sitters you leave your kids with when you go out. OK, so you can’t interview your child’s friend’s nanny, the neighborhood teen or his grandmother. But if you’ve learned a baby-sitter — not a parent — will be staying with the kids, you can ask the parents a few questions, such as: How old is the baby-sitter? Has she stayed with your children before? What activities does she have planned? Who will she contact in an emergency? Does she have any physical disabilities? Is she allowed to discipline the kids?
- 3. Is someone keeping an eye on the Internet? Better yet, is someone making sure the kids are not sending photos of themselves to strangers, or sharing their names or phone numbers? Evaluate the computer safety issue with these tips for kids — from Common Sense Media — and share them with your children and with their friends’ parents:
- • Visit only age-appropriate sites. Check out the site before your kids visit it. • Search safely. Use safe search settings for young kids or think about applying filtering software to limit inappropriate exposure. • Avoid strangers. Explain to your kids that if someone they don’t know talks to them, they shouldn’t respond, but should let you know. • Be a good cybercitizen. If your children wouldn’t do something in real life, they shouldn’t do it online. Find out how they can report mean behavior or unkind content on their favorite sites and teach them how to do it. • Use the computer in a central place. Keep the computer in a location where you can see what’s going on. • Avoid going online without a parent’s permission.
- 4. Will the kids be going out or staying home? Didn’t know your daughter would be going to that R-rated film? That’s because you didn’t ask. Which brings us to one of your sleepover goals: You’d like as few surprises as possible. Maybe the kids are just going bowling. You’d still like to know that; perhaps the roads are superslick and you’d rather your child not venture out on them. Don’t assume that just because your child arrived at his friend’s house, backpack, jammies and sleeping bag in tow, he’ll spend the evening lounging around the family room playing Parcheesi.
- 5. Anyone else in the house? Are there other relatives — cousins, uncles, grandparents — in the home? Will the teenage brother be entertaining friends? Make sure you — and your child — feel comfortable with any extended family or additional visitors who are present. Ask about sleeping arrangements: Will the kids be by themselves in a bedroom? On the floor in the playroom? Sharing a room with siblings?
- Pay attention to the way other parents answer these — and other — questions. If they’re offended by them or they claim you’re too protective or even worse, they simply laugh it all off, you might want to check out the movie at the local cinema, grab your child and a big bag of popcorn, and make a night of it.
- Linda Morgan is managing editor of ParentMap and the author of Beyond Smart: Boosting Your Child’s Social, Emotional, and Academic Potential. She is also an on-air parenting expert for KING TV.
Leaderboard
| Model | Automatic Evaluation | Human Evaluation | |||||
|---|---|---|---|---|---|---|---|
| Rouge-1 | Rouge-2 | Rouge-L | BertScore | Prefer Model | Prefer Gold | Tie | |
| DPR + BART | 39.8 | 12.4 | 23.0 | 0.881 | 13 | 52 | 35 |
| text-davinci-003 | 32.2 | 8.5 | 19.7 | 0.873 | 18 | 53 | 29 |
| DPR + text-davinci-003 | 35.4 | 9.2 | 20.2 | 0.868 | 56 | 15 | 29 |